
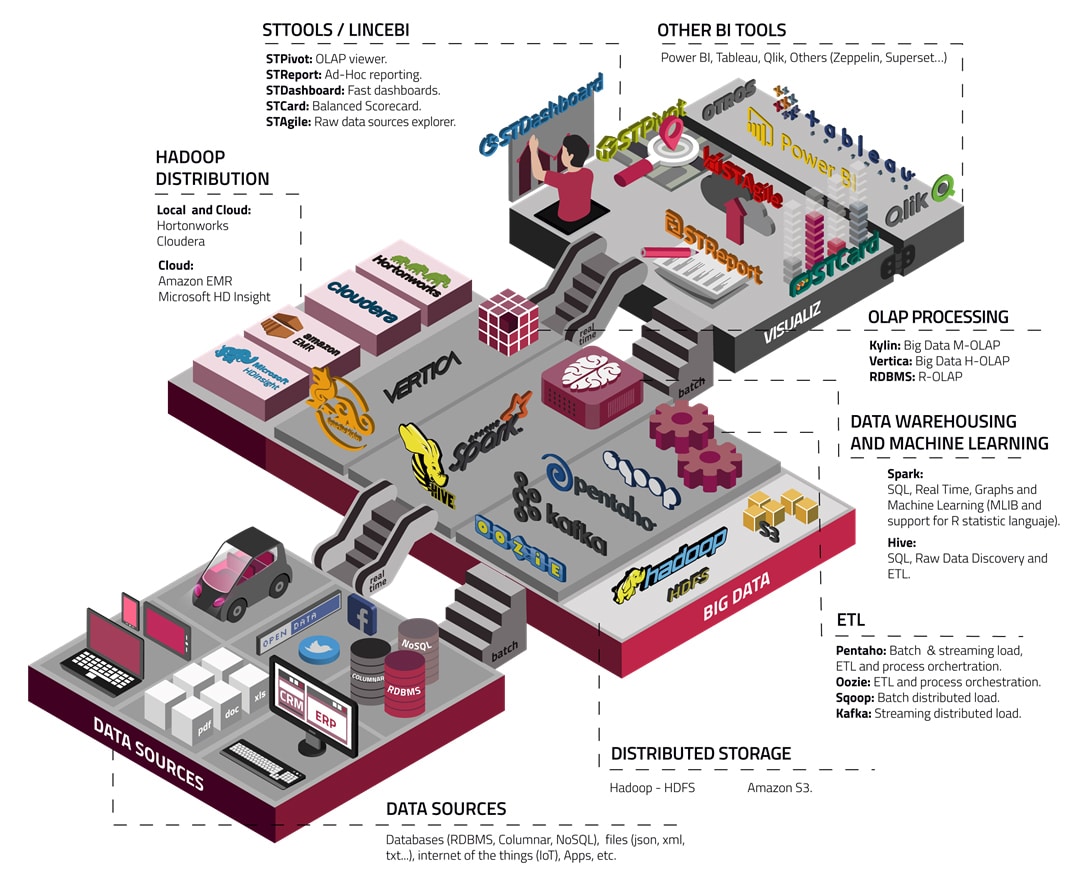
There are many technologies today that enable big data processing. However, choosing the right tools for each scenario and having the know-how to use them properly are very common problems in big data projects. For this reason, we at StrateBI have proposed the Big Data Stack, a choice of tools for big data processing based on our experience gathering requirements for big data analytics projects.
Our stack includes tools for each possible task in a big data project such as ETL (Pentaho Data Integration or Spark), Machine Learning (Spark, R o Python libs), Big Data OLAP (Kylin or Vertica) and also data visualization using our Lince BI – ST tools (Pentaho BA Server based) or other famous BI tools:
Sub second interactive queries over tables with billions of rows
While at the beginning existing big data technology allowed for very efficient data processing (e.g. Apache Hive or Cloudera Impala), analytical query times were no less than minutes or seconds at best case. This fact made very hard the use of big data technology for the implementation of data warehouses (as we knew them previously) to support analytics applications that require interactive response such as dashboards, reporting or OLAP viewers.
Analytics made by Kylin
Luckily, at the end of 2014 Apache Kylin was introduced. This open source tool is a distributed engine for analytical processing scenarios providing an SQL interface and supporting multidimensional analysis applications (OLAP) on a Hadoop/Spark cluster and over big data sources. The data from sources such as Hive, other common RDBMS (e.g. SQL Server) or even Kafka queues is pre-aggregated and stored in HBase (Kylin cube) by fast and incremental processes using Map Reduce or Spark engines.
These processes are automatically generated based on the cube definition provided by the Kylin users using its web UI. Once the cube is built, the users can perform SQL analytical queries over billions of rows with response times less than the second:

Moreover, thanks to the support for J/ODBC connectors and a complete API REST, Kylin can be integrated with any current BI tool. In our case, we have seamlessly integrated Kylin with our Lince BI – ST tools (Pentaho BA Server based): STpivot (OLAP viewer), STReport (reporting ad-hoc) and also with STDashoard (self-service dashboarding).
Digital marketing analytics real case
As with the other technologies in our stack, we have been able to successfully integrate Kylin into a real big data project. The project’s main goal was to analyze data from digital marketing campaigns (e.g. impressions metrics), customer base and payments for a worldwide company dedicated to develop mobile apps.
In the baseline scenario we had to load and transform more than 100 data sources with a very high volume, although most of them was structured data. Some of the source tables had more than thousand millions of rows of historical data and several millions of news rows were generated per hour. Until that moment, the customer processed this data using PHP processes and then stored it in a data warehouse infrastructure based on distributing the load between MySQL and Redshift (most complex queries).
With this system they achieved loading, refreshing and query times (latency) too slow for their business needs. Therefore, improving data pre-processing (ETL) and query latency were the main goals of the project.
That´s why we proposed and implemented an architecture that uses lots of tools from our stack: Sqoop (to load data), Hive (to pre-process data and as source for Kylin), Kylin (to query the resulting big data warehouse with sub second latency) and Lince ST Tools over Pentaho BA Server (to analyze and visualize the aggregated data). Thanks to the application of these tools, data load and refreshing times were reduced from 30 minutes to about 10 minutes. But the best improvement was the improved query latency due to the use of Apache Kylin, having most of the queries resolved in less than 1 second and between 10x and 100x faster than the initial scenario.
Big Data Benchmark
After successfully testing the power of Kylin, we decided to support this technology as a core part of our big data solutions. For this reason, we organized a workshop to present the Big Data Stack and Apache Kylin.
The first edition took place in Barcelona, with more than 30 attendees from big companies, most of them professionals in the field of BI. After the success of the event, we organized a second edition in Madrid, with the participation of Luke Han, creator of Kylin and CEO of Kyligence (Kylin Enterprise). We also had talks from companies where we have successfully implemented Kylin.

We also presented a benchmark whitepaper that compares the Big Data OLAP tools, Kylin and Vertica, and tests them against PostgreSQL (traditional BD). The results show that Kylin allows us to achieve the best query latency but Vertica (also part of our stack) also proved to be a very fast OLAP engine. This last event was a big success with more than 40 attendees from large companies based in Spain processing big data.
Other applications and use cases of the stack
In addition to the Big Data OLAP applications discussed, Big Data Stack provides tools for others applications such as data quality processes, real time processing and machine learning.
At the moment, we are carrying out a project using Spark and its machine learning libraries for implementing a data quality process to improve direct and promotional marketing. With Spark we are able to de-duplicate the data using advanced statistics or to cross the raw data of customers with addresses dictionaries and geo API’s to normalize and clean it.
Moreover, with Kafka we gather the data sources directly from our apps at real time or others API’s in order to process it using Spark Streaming and also to load this data in Kylin directly from Kafka to achieve near real time OLAP cubes.
Therefore, we can conclude that a solution stack with pure open technologies enables the successful implementation of most big data analytics scenarios of today. However, we will continue researching and testing new tools in order to enrich the Big Data Stack.
You could also like these articles: