Um beim Internet der Dinge der Konkurrenz standzuhalten und sie sogar zu übertrumpfen, sind IoT-Plattformen mittlerweile unverzichtbar geworden. Doch was ist wichtig bei der Auswahl der richtigen Plattform? Welche Voraussetzungen sind entscheidend, um eine IoT-Plattform erfolgreich zu betreiben?
In unserem Artikel erklären wir, wie Sie mithilfe von Open und Closed Source-Tools verschiedener Hersteller ihre eigene IoT-Plattform betreiben. Wir zeigen Ihnen den richtigen Aufbau einer Internet of Things Architektur, damit Sie aus Ihren IoT-Daten echten Mehrwert für Ihr Unternehmen ziehen.
Was ist eine IoT-Plattform?
Das Internet of Things hilft Ihnen unter anderem:
- Beim Einsparen von Energie
- Bei der Beseitigung von Schwierigkeiten und Herausforderungen entlang von Lieferketten
- Bei der Produktionssteigerung im Shopfloor-Management
Um echten Mehrwert aus Ihren Daten zu gewinnen, benötigen Sie jedoch eine IoT-Plattform.
Die Plattform hat die Aufgabe, Daten von IoT-Devices mit bestehenden Anwendungen über Schnittstellen miteinander zu verknüpfen, sodass sie automatisiert aufeinander reagieren können. Sie ist damit Übersetzer und zentrale Anlaufstelle im Internet der Dinge.
Die IoT-Plattform sorgt für die Anbindung der Devices und realisiert die Kommunikation zwischen den einzelnen, vernetzten Geräten mit den jeweiligen Applikationen.
Wie ist eine IoT-Plattform aufgebaut?
Je nach Anforderung benötigen IoT-Plattformen verschiedene Sensortypen. Diese verwenden jeweils eigene Protokolle oder Schnittstellen. Standardprotokolle sind beim Internet der Dinge beispielsweise MQTT, COAP und HTTP. Auch drahtlose Funk-Protokolle wie NB-IoT oder LoRaWAN kommen zum Einsatz.
Die einzelnen IoT-Komponenten umfassen Hardware, Software und andere Teile, aus denen das Internet of Things System besteht. Hardwarekomponenten sind unter anderem Sensoren, Aktoren, Edge-Devices und Mikrocontroller, welche die Daten sammeln und verarbeiten. Auf Software-Seite greifen Unternehmen in der Regel auf Cloud-basierte Plattformen zurück, die sich um das Speichern, Analysieren und Visualisieren der auszuwertenden Daten kümmern.
Praxisbeispiel – vom Konzept bis zur fertigen Internet of Things Plattform
Die Ausgangslage für unser Praxisbeispiel einer IoT Plattform ist folgende:
- Ein Industrieunternehmen mit verteilten Werksstandorten
- Folgende Daten fallen an:
- Prozessdaten von Maschinen
- Feldsensoren von bzw. Autos, Logistiksensoren
- Stationäre Sensoren (Wetter- und Bodendaten)
- Die Daten müssen zwischen den verschiedenen Werken ausgetauscht werden
- Daten müssen in Echtzeit – auch aus der Cloud – bereitgestellt werden
- Wichtig: Die Prozessdaten sollen lokal in der werksinternen Private Cloud bleiben
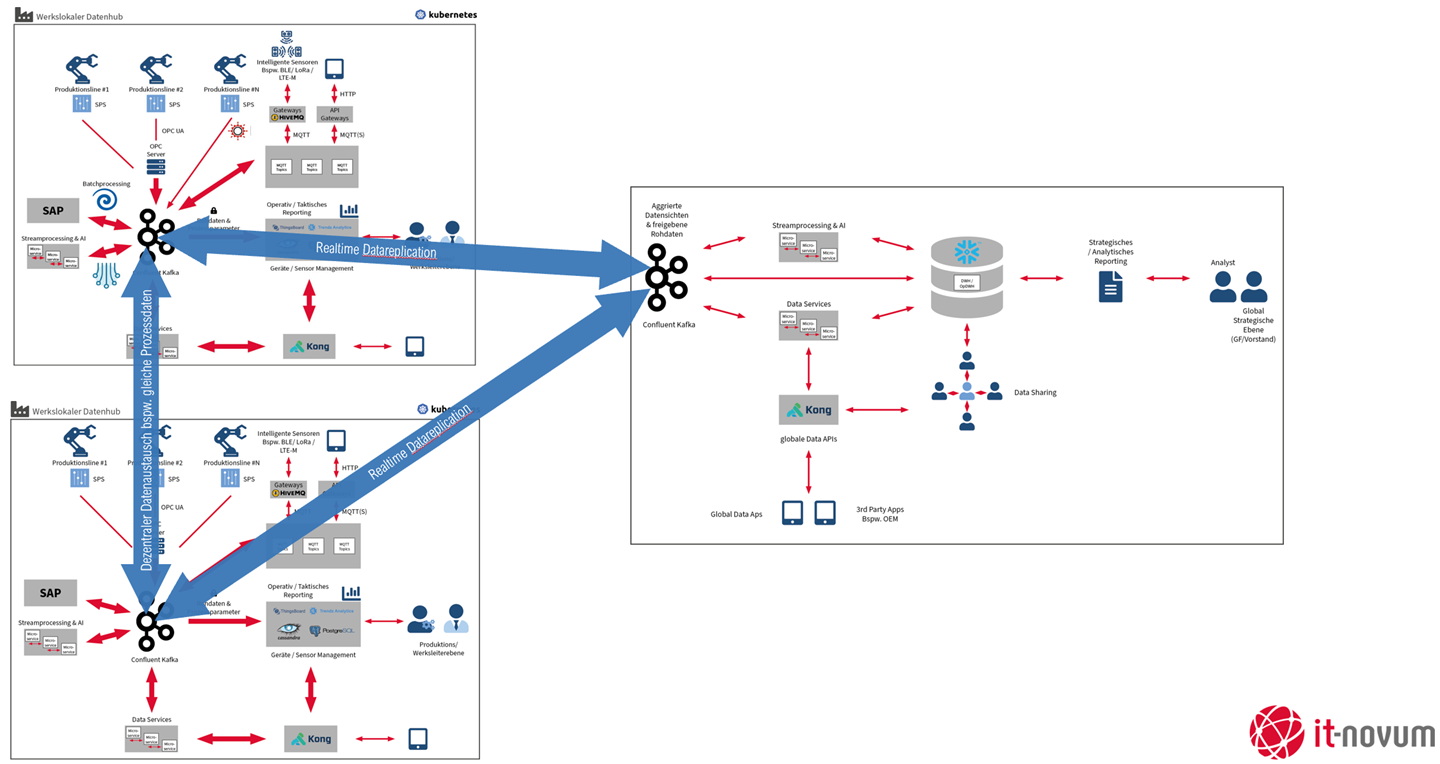
Zum Aufbau einer entsprechenden IoT-Architektur verwenden wir die Technologien, die in der folgenden Grafik zu sehen sind:
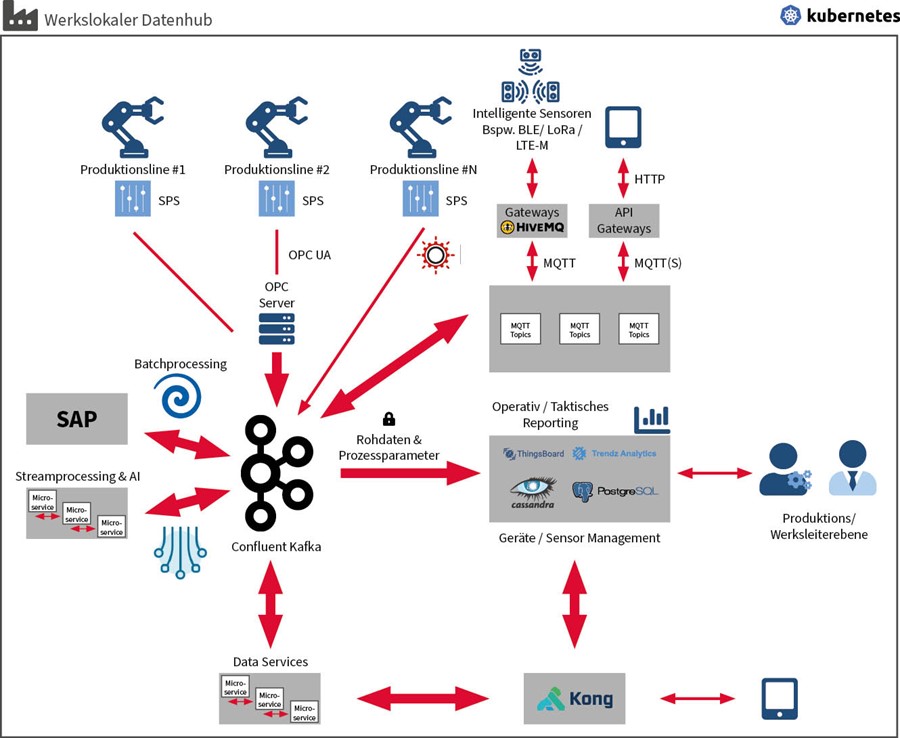
Integration von Feldsensoren über ein Gateway Pattern
Wie bereits weiter oben beschrieben, gibt es verschiedene Kommunikationsprotokolle wie LoRa, NB-IoT, BLE, RFID, welche die Konnektivität gewährleisten. Diese Protokolle über ein einziges Protokoll einzubinden, funktioniert nicht, weshalb im Rahmen dieses Beispielprojekts ein Gateway Pattern verwendet wird.
Jeder Sensortyp bzw. Protokolltyp stellt eine sogenannte Gateway-Komponente bereit, die dann ein harmonisiertes Protokoll an die Plattform schickt. Als Standard-Protokoll dient MQTT.
Was ist MQTT?
MQTT wurde ursprünglich entwickelt, um Ölpipelines zu überwachen. Es skaliert über Millionen von (Sensor) Verbindungen und basiert auf TCP. TLS dient als Verschlüsselungsschicht.
MQTT implementiert das Publish / Subscribe Pattern. Dabei schicken Sensoren die Daten, das sogenanntes Topic. Ein Auto hat beispielsweise einen Speed-Sensor. Die Daten des Sensors, zusammen mit dem Nummernschild, gehen an den MQTT-Broker, der entsprechend abonniert werden kann. Der Payload ist variabel, sodass Daten nach Bedarf verschickt werden können. MQTT lässt Millionen von Verbindungen bzw. Topics zu, ist TCP-basiert und unterstützt TLS.
Zu den Besonderheiten zählen:
- Pro Client kann ein Quality of Service Level eingestellt werden
- 0 = Fire and Forget
- 1 = at least once
- 2 = exactly once
- Testament Messages. Wenn vom Gerät die Verbindung unterbrochen wurde oder andere Fehlermeldungen auftauchen, kann in Echtzeit der Status vom Gerät beispielsweise von Online zu Offline gesetzt werden.
- Heartbeats. Automatische Heartbeat-Nachrichten an die Sensoren. Zum Beispiel werden halb-offene TCP-Verbindungen automatisch geheilt.
- Retained Messages. Speichert die letzte Message in einem Topic (z.B. letzter Standort).
- Shared Subscriptions. Mehrere Subscriber bekommen per Loadbalancing entsprechende Nachrichten.
- Queued Messages. Falls der Subscriber wegen einer Störung offline geht, nimmt der Broker die Nachtrichten auf, die der Subscriber verpasst hat. Der Subscriber bekommt die verpassten Nachrichten, sobald er sich wieder verbindet.
Komponenten der IoT Architektur
Die Wahl des MQTT-Brokers: HiveMQ
HiveMQ verfügt über ein starkes Extentions SDK, welches unter anderem Authentifizierungs-Provider und Eingriffe in MQTT Lifecycle Events erlaubt. Durch HiveMQ Swarm können MQTT-Clients simuliert werden. HiveMQ besitzt außerdem nützliche Enterprise Features wie beispielsweise OCSP Stapling.
Integration vom OPC-Router
Mit dem OPC-Router kann auch bei hohen Abtastraten modelliert werden. Der OPC-Router ist dank seiner einfachen Bedienung auf industriellen PCs lauffähig und besitzt viele Plugins und Schnittstellen zu Kafka, Cassandra, MQTT u.v.m.

Apache Kafka als Event Streaming Plattform
Apache Kafka ist ein verteiltes Commit Log, das nach dem Push/Pull-Prinzip funktioniert. Producer pushen Nachrichten und Consumer ziehen sie sich. Producer und Consumer sind voneinander unabhängig. Kafka ist in Topics organisiert und alle Topics, welche die Producer schreiben und welche die Consumer lesen, werden auf der HDD gespeichert. Das bietet die Möglichkeit des Offline-Consumings, ohne dass man schnell an die Arbeitsspeichergrenze stößt.
Consumer teilen sich Partitionen automatisch auf, was zu einer hervorragenden Skalierbarkeit führt.
Für einen erweiterten Funktionsumfang verwenden wir in unserem Beispielprojekt Confluent als Plattform. Confluent ist eine erweiterte Kafka-Distribution mit Enterprise-Features. Nützliche Enterprise-Funktionen von Confluent sind beispielsweise Tiered Storage, die den Storage durch reine Storage-Knoten erweitern, wohingegen beim reinen Kafka weitere Broker nötig sind. Damit sparen Sie zusätzliche Netzwerkressourcen ein. Eine weitergehende Rechte-Steuerung lässt Ihnen zudem mehr Freiheiten beim Vergeben von Rechten.
Zu den Highlights von Kafka gehören:
- Cluster Linking / Replication: Realtime Synchronisation von Topics und Consumer Offsets zwischen Clustern (CL Enterprise Feature)
- Schema Registry: Dort sind Schemata hinterlegt. Diese sind nach Versionen abrufbar
- Big Data & Microservice Integration
- Enterprise Security Options: Encryption, Authentication, etc.
Warum MQTT und Kafka eine gute Kombination sind
MQTT:
- Ist optimiert für Monitoring von Devices & Sensoren
- Besitzt eine tiefe Topic Struktur, Millionen von Topics
- Millionen von Connections
- Data Connection, Rückkanal, M2M
- Ist nicht geeignet für Analytics
Kafka:
- Ist optimiert für die Datenbereitstellung der Sensordaten für die Verteilung im Unternehmen
- Besitzt eine flache Topicstruktur (skalierbar über Partitionen)
- Besitzt einen hohen Durchsatz (zum Beispiel Big Data, Streaming Analysen, etc.)
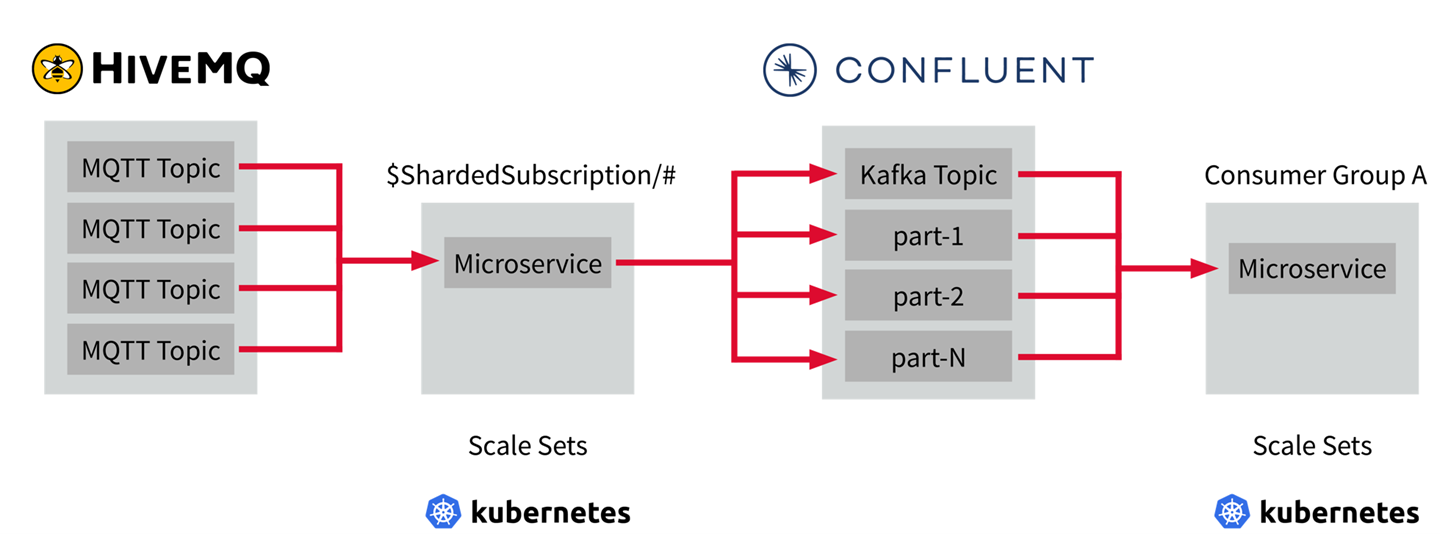
Skalierung von MQTT und Kafka
HiveMQ ist sowohl ein MQTT-Broker als auch eine client-basierte Messaging-Plattform, die Daten zwischen IoT-Geräten und Maschinen hin und her transportiert. Die Plattform verwendet das MQTT-Protokoll, um zeitnah bi-direktional Daten zwischen Geräten und Unternehmenssystemen auszutauschen.
In HiveMQ gibt es die Shared Subscriptions. In der Bereitstellungs- und Verwaltungssoftware für Containeranwendungen Kubernetes können Scale Sets angelegt werden, welche die gleiche Shared Subscription haben aber mit Microservices darin. In Kafka gibt es die Consumer Groups, die sich auf Partitionen aufteilen. Wenn dann die Anzahl der Microservices im Scale Set erhöht wird, erreicht man mit diesem Setup eine automatische Skalierung der Verbraucherservices auf HiveMQ & Kafka.
Unsere Empfehlung: Dieses Setup in einer Container-Umgebung wie beispielsweise Kubernetes betreiben.
Use Cases für die Datenaufbereitung
Daten können Sie auf zwei Weisen verarbeiten: Per Stream- oder Batch-Processing. Das Batch-Processing verarbeitet Daten nicht in Echtzeit. Es verarbeitet große Datenmengen, führt komplexe Berechnungen durch und erstellt Reportings.
Stream-Processing verarbeitet Daten in Echtzeit.
Für Stream Processing:
- Sensor Monitoring
- Operatives Reporting & Alerting
- ML-Application
- Realtime Push Notifications
- ML-Training (Online)
Für Batch Processing:
- Nutzungs-Reports
- Financial Reporting
- Analytisches Reporting
- ML Training (Batch)
Die Wahl für das Batch Processing: Pentaho
Pentaho ist ein Open Source Datenintegrations- und Analytics Tool, welches es sowohl als Community- als auch als Enterprise-Edition gibt. Die Enterprise-Edition verfügt über zusätzliche Features wie beispielsweise SAP-Integration (von it-novum), SAML, Enterprise Steps (Big Data Plugins / Machine Learning, etc.). Pentaho ist eine Low-Code Plattform mit hunderten von Transformationen und Konnektoren. Das integrierte Plugin-Framework erlaubt ein einfaches Erweitern um weitere Funktionalitäten.
Die Wahl für das Stream Processing: Kafka Streams / KSQLDB
Kafka Streams erlaubt eine einfache Integration in Microservice Frameworks (z.B. Micronaut). Es sind keine zusätzlichen Services und Infrastrukturen erforderlich. KSQLDB als Datenbank erlaubt das Nutzen von Kafka Streams und besitzt ein REST Interface.
Bereitstellung von Data APIs: Kong und Micronaut
Um eine zentrale Schnittstelle für Services anzubieten, wurde als Pattern ein sogenanntes API-Gateway verwendet mit dem Ziel, eine einheitliche Schnittstelle pro Werk zu haben. Außerdem dient das Gateway als Grundlage für den Datenaustausch und die Demokratisierung und ist zudem für die Authentifizierung und Autorisierung verantwortlich.
Das API-Gateway Kong gibt es als Open Source oder in der Enterprise-Variante. Kong ist extrem schnell, mit nur geringen Latenzen durch das Gateway. Ein mächtiges Plugin-Framework (LDAP, Oauth, JWT) zeichnet Kong aus. Kong unterstützt unter anderem gRPC, HTTPS, GraphQL und TCP.
Micronaut wird als Framework für Microservices eingesetzt. Bei Micronaut handelt es sich um ein Open Source Java Microservice Framework. Zu den Stärken von Micronaut gehört die Unterstützung von native GraalVM, das Templating mit diversen Systemintegrationen und eine einfache CI-Integration.
Management der Devices und Sensoren
Um Sensoren und Geräte umfassend und sicher zu verwalten, ist eine weitere Software nötig. Dazu zählen die Echtzeitsicht auf Sensoren und Datenpunkte (Dashboarding), Implementierung von Alarmen und Regelketten, Management von Assets Asset-Hierarchien und andere Eigenschaften.
ThingsBoard: Die Lösung für Monitoring und Alerting
Die Open Source Software ThingsBoard ist eine IoT-Plattform, die auf einer vollständigen Microservice-Architektur beruht und für die Visualisierung der Daten zuständig ist. Mit ihr können einfach und schnell Realtime-Dashboards gebaut werden, Daten von IoT-Devices verwaltet und gesammelt sowie IoT-Analytics durchgeführt werden. Das Tool ist über zahlreiche Plugins erweiterbar. Die Datenspeicherung erfolgt über ein hybrides Setup. Eine Postgres-Datenbank dient zum Speichern von Metadaten, Nutzerdaten und Assets. Die Cassandra-Datenbank ist für das Speichern der Telemetrie-Daten zuständig.