Die Rolle von DataHub als leistungsstarker Datenkatalog
Warum DataHub für Versicherungen besonders relevant ist
Versicherungen agieren in einem Umfeld, das von umfangreichen und komplexen Datenbeständen geprägt ist. Diese Daten umfassen unter anderem Kundendaten, Vertrags- und Schadensinformationen sowie regulatorische Berichte und Compliance-Daten. Gerade große Versicherungsunternehmen setzen häufig auf große Datenbankmanagementsysteme wie Oracle, IBM oder Microsoft als zentrale Data-Warehouse-Systeme.
Die Komplexität dieser Systeme führt jedoch häufig zu erheblichen Problemen. Mangelnde Transparenz stellt eine der größten Herausforderungen dar, da Datenquellen und -strukturen oft unübersichtlich dokumentiert sind. Hinzu kommen isolierte Datensilos, die in unterschiedlichen Abteilungen existieren und die bereichsübergreifende Zusammenarbeit erheblich erschweren. Ein zentrales Problem ist die oft unklare Datenherkunft, die durch Data Lineage gelöst werden kann. Denn Unklarheiten über Ursprung, Verarbeitung und Nutzung von Daten führen häufig zu Unsicherheiten in der Entscheidungsfindung und im Reporting.
Automatisierte Dateneinspielung mit DataHub Recipes
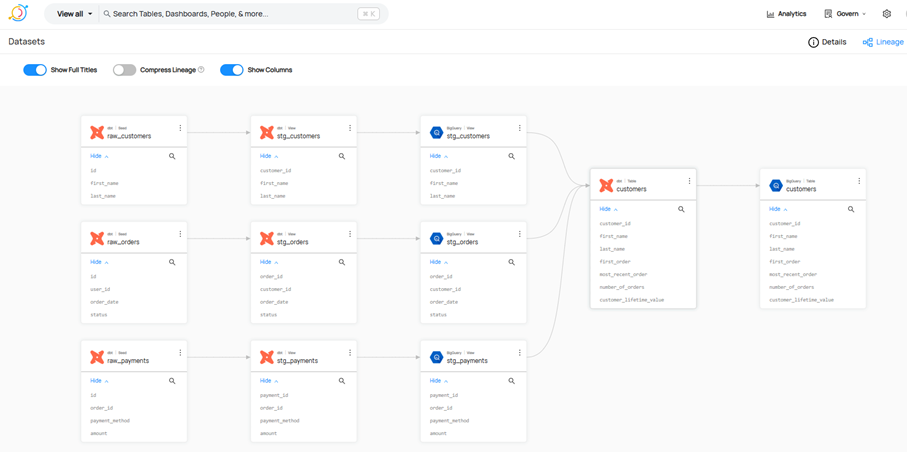

In diesem Beispiel wird ein Oracle-Datenbankserver mit dem Hostnamen oracle-db.myinsurance.com und dem Schema INSURANCE_SCHEMA angebunden. Die sink-Konfiguration definiert die Zielplattform – in diesem Fall der DataHub-Server.
Zur Ausführung dieser Recipe wird das folgende Kommando verwendet:
Diese einfache, aber leistungsstarke Methode erlaubt es, große Datenmengen effizient und zuverlässig in DataHub einzuspeisen. DataHub erfasst dabei nicht nur die Tabellenstruktur und Feldnamen, sondern auch umfassende Metadaten, wie z.B. Datentypen, Primär- und Fremdschlüsselbeziehungen sowie Data Lineage-Informationen.
Data Lineage speziell in Oracle-Umgebungen mit DataHub
Die Data Lineage-Funktionen von DataHub unterstützen nicht nur die technische Dokumentation, sondern bietet auch konkrete Mehrwerte im operativen Geschäft. Besonders in Oracle-Datenbankumgebungen, die durch zahlreiche Stored Procedures, Trigger und komplexe Datenbankprozesse gekennzeichnet sind, schafft DataHub Klarheit über die tatsächlichen Datenflüsse. Um die Nachvollziehbarkeit weiter zu verbessern, haben wir ein spezielles Plugin für den Oracle Data Integrator (ODI) entwickelt, das die gesamte ETL-Logik erfasst und in die Data Lineage-Analyse integriert.
Durch die nahtlose Anbindung an den ODI ermöglicht unser Plugin eine detaillierte Visualisierung der Datenbewegungen – von den Quellsystemen über Views, Transformationen, Joins und Aggregationen bis hin zur finalen Bereitstellung der Daten in Berichten und Dashboards. Dies hilft Unternehmen, selbst hochkomplexe Datenströme zu verstehen und regulatorische sowie operative Anforderungen besser zu erfüllen.
Versicherungsunternehmen müssen insbesondere in der regulatorischen Berichterstattung ihre Kundendaten effizient verwalten und die Transparenz der Datenherkunft sicherstellen, um fehlerhafte Berechnungen zu vermeiden. Mithilfe unseres ODI-Plugins für DataHub können Unternehmen nun nicht nur sämtliche relevanten Datenquellen identifizieren, sondern auch erkennen, an welchen Stellen im ETL-Prozess Transformationen, Filterungen oder Aggregationen vorgenommen wurden. Dies führt zu einer erheblichen Reduzierung von Berichtsfehlern und verbessert die Revisionssicherheit.
Darüber hinaus bietet unser Plugin weitere entscheidende Vorteile:
- Automatisierte Erfassung von ODI-Transformationen: Neben der reinen Datenherkunft werden auch komplexe ETL-Logiken, wie Joins, Filter und Aggregationen, in der Lineage abgebildet.
- Optimierung der Datenqualität: Data Stewards und Fachabteilungen können Transformationen und Berechnungen transparent nachvollziehen und inkonsistente oder fehlerhafte Daten schneller erkennen.
- Effizienzsteigerung im Datenmanagement: Durch die Identifikation redundanter ETL-Prozesse können Unternehmen ihre Datenverarbeitung optimieren und Ressourcen effektiver nutzen.
- Verbesserte Compliance & Auditsicherheit: Die vollständige Nachverfolgbarkeit der Datenherkunft erleichtert Audits und regulatorische Prüfungen.
Durch den Einsatz unseres Oracle Data Integrator-Plugins für DataHub profitieren Unternehmen von einer noch tieferen Integration ihrer Oracle-Datenprozesse in die Data Lineage. Dies macht es einfacher, kritische Datenflüsse zu analysieren, Fehlerquellen zu eliminieren und die Datenverwaltung insgesamt effizienter zu gestalten. Gerade für Versicherungen, die stark von verlässlichen Daten für Risikobewertungen, Schadensanalysen und regulatorische Berichte abhängig sind, stellt diese Lösung einen entscheidenden Vorteil dar.
Verbesserung der Datenqualität und Dokumentation mit DataHub
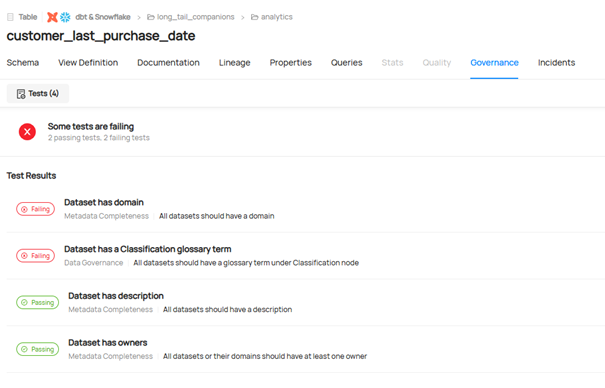
Ein wesentlicher Aspekt eines erfolgreichen Datenmanagements in der Versicherungsbranche ist die Sicherstellung einer hohen Datenqualität und umfassenden Daten-Dokumentation. DataHub bietet umfangreiche Funktionen zur Verbesserung der Datenqualität durch automatisierte Validierungen, Konsistenzprüfungen und die Verfolgung von Änderungen an Datenbeständen.
Durch die detaillierte Dokumentation von Metadaten, wie z.B. Datentypen, Beziehungen und Transformationen, erhalten Unternehmen ein vollständiges Bild ihrer Datenlandschaft. Dies verbessert nicht nur die Genauigkeit von Analysen und Berichten, sondern reduziert auch den Aufwand für Audits und regulatorische Prüfungen. DataHub unterstützt zudem Data Stewards und Analysten durch intuitive Dashboards und Abfragefunktionen, um potenzielle Qualitätsprobleme frühzeitig zu erkennen und gezielt zu beheben.
Fazit und nächste Schritte
Die Implementierung eines leistungsstarken Datenkatalogs wie DataHub bietet für Versicherungsunternehmen erhebliche Vorteile. DataHub verbessert die Transparenz, reduziert Fehlerquellen und fördert eine datengetriebene Unternehmenskultur. Besonders in komplexen Oracle-Datenbankumgebungen ist die Fähigkeit von DataHub, vollständige und detaillierte Data Lineage abzubilden, ein entscheidender Erfolgsfaktor. Die Kombination aus automatisierter Metadaten-Erfassung, leistungsstarken Data Lineage-Funktionen und flexiblen Integrationsmöglichkeiten macht DataHub zur idealen Lösung für die Versicherungsbranche.
Bei Fragen stehen wir gerne zur Verfügung. Falls Sie DataHub in Aktion erleben möchten, empfehlen wir Ihnen einen kostenlosen Demo-Account auf der it-novum Website. Zudem finden Sie auf dem it-novum YouTube-Kanal umfassende DataHub-Playlists und spannende Inhalte. Lassen Sie uns gerne über Ihr individuelles Datenkatalogprojekt sprechen!