
200 people from almost 40 countries have come to Mainz, Germany to join for the 10th Pentaho Community Meeting. I didn´t believe this day could come true but all of a sudden it was there! Between the old walls of Kupferbergterrassen and a huge sculpture of Bismarck’s head we celebrated ten years of a great user and developer community with a community meeting that has never been so big.
24 speakers from all parts of the world presented their newest developments and usecases and shared them with the community (you can find all presentations slides in the HDS Community):
- Pedro Alves: What´s new in Pentaho 8.0?
- Jens Bleuel: Worker Nodes in Pentaho 8.0
- Matt Casters: What’s brewing in the kettle?
- Jill Ross: Pentaho in the Hitachi Vantara Community
- Jan Janke: CERN: Pentaho in a huge international organization
- Devan Manharlal: Using Pentaho in the public health system
- Stefan Müller: Making SAP data accessible
- Kamil Nesetril: Integrating environmental data with Pentaho
- Bart Maertens: Migrating from Microsoft to Pentaho
- Raimonds Simanovskis: eazyBI
- Balázs Bárány: Running Pentaho without developers
- Francesco Corti: Pentaho 8 Reporting for Java Developers
- Caio Moreno de Souza: Leveraging Machine Learning with AutoML and Pentaho
- Alain Debecker: ETL-Pilot (Data Load Supervision Dashboard)
- Diethard Steiner: Pentaho Standardised Git Repository Setup
- Slawomir Chodnicki: Continuous integration with PDI
- Hiromu Hota: WebSpoon and SpoonGit for Pentaho PDI
- Kleyson Rios: Pentaho CDE NewMapComponent
The first Pentaho Community Meeting was omnipresent, at least as table cloth on the table that carried the memorabilia for the action and charity run tonight. It´s unbelievable – besides Jens and Pedro there were five other attendees that had already participated in the first community meeting. Most attendees might have wondered which implications will the rebranding of Pentaho to Hitachi Vantara have for the Pentaho community. To say it with Pedro: „This!“ – the fact that Pentaho Community Meeting was taking place showed that Hitachi Vantara is putting much focus on the community and Pedro expects more community meetings to come.

In his welcome speech, Jens Bleuel (btw coming from and still living and working in Mainz) pointed out that when he joined Pentaho he had many doubts whether it would be the right decision: could a US company with a hire and fire mentality fit with his current life situation (two little children)? Some years later, he found that he had made the right choice when he was organizing the first community meeting. At that time, PCM had 38 attendees and when visiting the venure and seeing huge Bismarck hall
at Kupferbergterrassen, Jens thought „What if one day we could fill this one?“ Well, nine years later here we are: more than 200 participants from three dozens of countries easily fill the hall.
What´s new in Pentaho 8.0?

Pedro gave a short introduction to Pentaho 8.0. One of the bigger feature of the release are worker nodes for scaling out. When executing jobs you can now execute jobs everywhere, not only locally. The goal is to have this execution option to everything in Pentaho. Concerning Pentaho Data Integration, the new version supports streaming support, runf configurations for jobs and data explorer filters
(enhanced data inspection features, numeric filters, string filters, inclusion/exclusion options for data points. Jens gave more details on that in his talk.
Scaling out the Pentaho platform in large enterprise operations: Worker Nodes

Jens dug a littler deeper in the feature though probably not as much as he would have liked to 🙂 Worker nodes can scale work items across multiple nodes (containers), f.e. PDI jobs and transformtions, report executions… They operate easily and securely and have an elastic architecture. Large enterprises need the ability to seamlessly and efficiently spin up resources to handle 100s+ work items at different times, with different dependencies and processing requirements. Worker nodes address these needs. The difference to AEL and Hadopp MapReduce is that whereas they only scale out on data worker nodes scale
out on processes (PDI jobs, PDI transformations etc.). You can even combine these two architectures to use both of them in an advanced way and get a better ROI.
What’s brewing in the kettle?

As usual, Matt’s speech included a lot of code. He showed new things from the Pentaho labs like the streaming plugin. There are many things currently going on in the Kettle kitchen that was set up more than 10 years ago – obviously it is still cooking vividly. As in Hitachi Vantara many people are using PDI Kettle is far from becoming out-dated. There are lots of plans about using PDI with new technologies like blockchain or Kybernetes.
Matt remembered how 9 years ago there were many topics on the wishlist – today, most them have become true. Matt encouraged people to use the Pentaho Community Meeting to give feedback and share new ideas on PDI.
Pentaho Community in Hitachi Vantara Community
Jill Ross, Community Manager at Hitachi Vantara, introduced Hitachi Vantara Community. Hitachi Vantara Community is a social collaboration network that was created in 2013 to give employees, customers, partners and prospects the possibility to interact, ask questions, join discussions, share knowledge and learn from people at Hitachi Vantara. Clearly, the purpose of it is to get answers, discover insights and make connections and there are many technical discussions and sharing solutions and usecases going on. Pentaho community is now integrated in Hitachi Vantara so should be discussions about problems and bugs. As the community is huge, there are different places where people can gather to share
and create content and jointly work on solutions. You see, there are quite a few benefits to join the community (btw: we have already created a page for Pentaho Community Meeting 2017 two months ago there!).
CERN: Pentaho in a huge international organization

Expectations were high when Jan Janke entered the stage and they even increased with his fancy animated galaxy start screen. CERN is the world’s biggest particle physics research organization funded principally by its member states. At CERN, currently 2,300 staff members, 1,600 fellows, students and associates as well as more than 12,000 visiting scientists are working. The laboratory’s main purpose is to study sub-atomic particle with the goal to understand better the universe. To do this, CERN runs particle accelerators and among them its flagship LHC (Large Hadron Collider). While enabling researchers from all over the world to conduct particle physics experiments, CERN is also the place of birth of the World Wide Web, is at the forefront of developments in areas such as high precision welding or medical imaging and has put in place a world-spanning computing grid (which existed before the “cloud”).
Running an organization such as CERN creates its own business challenges. Pentaho is used in many different areas by the Administrative Information Systems (AIS) group. It has become the backbone of its BI, reporting and analytics infrastructure. Pentaho Analyzer is used by business experts from various domains. It is especially appreciated for its ease of use and its capability to provide a fast insight into various business processes in an ad-hoc manner. Because it is so easy to get going with Analyzer, the users’ demands are also very high. Providing durable good performance is still an area that CERN’s engineers are working on.

As highlighted during the talk, CERN is located on top of the Franco-Swiss border and as Switzerland is not part of the EU, the organization faces many different customs procedures on a regular basis. An important number of the needed forms is generated with the help of Pentaho Report Designer (PRD). Furthermore, CERN leverages Pentaho’s APIs and the ease of embedding it within its own applications to provide all kind of reporting self-services to its employees and users.
CERN is not (yet) using Pentaho for big data. It is however used for data integration, reporting and ad-hoc analytics and operating with data provided by a data warehouse that is kept up to date in near real time. Being an international organisation, an important amount of sensitive data not usually found in regular companies is being handled. Examples are social security, childcare, health insurance or even medical data. Such sensitive data is subject to many restrictions and CERN need to put a particular focus on data protection.
In addition to Analyzer and PRD reports, CERN is also a heavy user of CTools. The CTools are used to build dashboards and KPIs for the different management layers. Pentaho is mostly embedded in CERN’s applications so not all of the 15,000 potential users at CERN are logging directly into Pentaho’s User Console. The organization is also heavily relying on Pentaho Data Integration (PDI) for its data
warehousing ETL processes. During the Q&As, Jens of course wanted to have more details about CERN’s ETL processes. Jan confirmed that they use PDI a lot but „ETL is just assumed to be working“.

Using Pentaho in the public health system

Mozambique is a country facing many challenges and Devan Manharlal started his talk with some of them: 7,800 nurses are serving 27 million Mozambiquans – in Germany, there are 1 million (!) health workers for a population of 85 millions. Mozambique is among the bottom 10 countries on WHO’s 2010 list of nations with serious health workforce shortages. To help to address these issues it was important to make health data available in order to analyze it to understand better the current situation and develop solutions (where do nurses live and where are facilities in need of nurses located?).
To do so, the Ministry of Health has developed a national human resources for health information systems (HRIS or eSIP-Saude), to improve the planning and management of healthcare workers countrywide.
As Mozambique has a lot of different HRSIs systems, software and other data sources that aren´t connected with each other, the goal was to establish an integrated data system.
Making SAP data accessible: Pentaho/SAP Pentaho

74% of all world transaction worldwide touch a SAP system. But working with SAP is not easy: migrating or exporting SAP data is almost impossible (f.e. if you want to use them for strategic decisions), data quality is oftentimes poor etc. etc. When it comes down to data integration, SAP has a proprietary format and structure, a steep learning curve for developers and so SAP programmers can be a “bottleneck” in an organization as they´re mostly not nearly as available as you would like them to be…
So, everyone knows the “solutions” coming out of this: hand-coded applications that are oftentimes limited to single individuals or departments and can´t be used somewhere else in the organization. And for developing them you rely on SAP programmers or individuals that can´t be easily replaced. Pentaho’s open APIs allow for integrating SAP data, however only to a limited extent as existing solutions like SAP Input Step haven´t been updated for a longer time. Other ones are limited to HANA and so on.
That´s why it-novum has developed the Pentaho/SAP Connector. The connector offers a broad spectrum for processing SAP data and supports the current PDI version, metadata injection, using variables, filter functionality, selecting fields, mapping SAP/Java data types, SAP table read and BAPI querying. Backed by a smartphone hotspot Alex Keidel then ran a demo on how to integrate SAP BW data with the connector. This raised the question
of how a software that is used around the globe still sticks to German abbreviations for KPIs: for sure, no one outside Germany might be familiar with „Vertriebsbelegposition“.
Integrating environmental data with Pentaho
The next presentation came from the Czech Republic and covered the topic of environmental information systems. Kamil Nesetril from Liberec Technical University presented the Hydrogeological Information System that is based on Pentaho. dataearth.cz uses the entire BI stack of Pentaho. This way it brings BI tools and concepts to the world of groundwater and environment that only knows Excel for working with data. According to Kamil, challenges lie less in the field of data volume (big data) but in diversity of data as a lot of semi-structured and long-tail data has to be processed. Kamil
impressed with the remark that he is not only using all the tools of the Pentaho platform but also many different environmental software solutions. Isn´t that a heavy user?!
Migrating from Microsoft to Pentaho
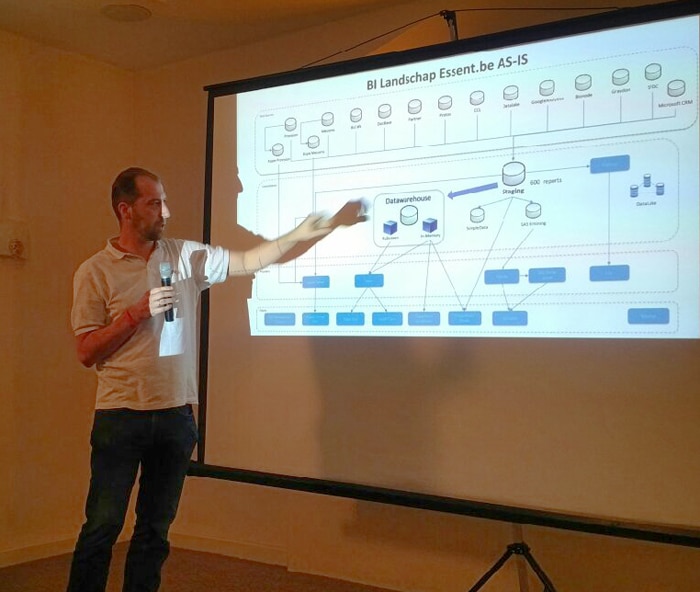
A special case of data integration was in the center of the next talk: Bart Maerten from know.bi presented the migration from Microsoft to Pentaho at Essent Belgium. Previously, Essent used Provision, a Microsoft, on-premise solution but wanted to shift to a cloud-based approach.
NOVA, the new system, is based on open source technologies and AWS. It was to be easily rolled out to other sites and group companies and that´s why Essent chose a cloud solution. Other reasons were scalability, efficiency and costs. The project started in 2015 with selecting the platform (Pentaho won over Jasper). During 2016 the environment was built and then the migration started which posed some challenges. At the end of February, the first B2B platform was released with the B2C version planned for beginning of next year.
The project team consisted of a traditional BI part with analysts, developers for the ETL processes, reports and dashboards and the project owner/manager. On the analytics side, four people data scientists and software engineers joined. The new solution is based on AWS and Pentaho and uses the ETL, Analyzer, Dashboards Designer and Reporting modules of Pentaho. Concerning AWS DMS, Bart only commented „it is quite ok if it works“.
NOVA loads data from more than ten systems to a landing area. Here, ETL processes transform the data to load it in a Postgres database before it can be transfered in the data warehouse. Data visualizations and analyzes are run on the logical area that is somewhere in between of these steps.
Lessons learnt included the surprising finding that starting a BI development without real-life data is hard. Also, AWS sometimes bites: it definitely has a lot of advantages but also
some failures and it took some time to solve them. The agile developing method the team had adopted at the beginning proved to eventually pay off but it needs to be done well.
A data analytics app based on Mondrian

Raimonds Simanovskis started his presentation with the surprising fact that it was painter Piet Mondrian who back in 1900 created the first data visualizations and called them „Tableau 1“. Not convinced? Well, that´s what happens when a 21st century developer visits German museums… Raimonds introduced eazyBI, an easy-to-use BI application designed for Jira customers to
analyze data and build reports, charts and dashboards from Jira, Jira add-ons, and other data sources. More information in this interview with Raimonds and on eazybi.com.
Running Pentaho without developers
Balázs Bárány presented a pure business use case, Austria’s first scooter sharing service SCO2T. The sharing platform works like common car sharing services and relies exclusively on open source technologies. SCO2T was founded in 2014 with first scooters rented in early 2015. Today, it offers 90 scooters that serve 6,000 customers. The interesting thing about the project is that Balázs is not a developer but a data scientist without profound programming skills. He therefore has a different and interesting view on Pentaho.

When setting up SCO2T, Balázs faced the usual challenges startups have to deal with like missing manpower and money, little experience with doing business and sometimes having to invent things from scratch. Austria and particularly Vienna are a very complex regulatory environment for sharing services in the transportation sector. And, amazingly for being a internet-based startup, the team did not have a software developer. So, Balázs decided to use a solution he already knew: Pentaho. As it was open source it was also quite economic.
SCO2T uses almost all components of the Pentaho platform: Pentaho Data Integration serves purposes ranging from the application of business rules (registration confirmations, reminders, creation of line items for invoices, calculation of ride lengths and prices) to billing (invoice creation, data export for accounting and bank communication) and operations (vehicle position & state alarms, replication of data between databases). The BI/BA server is the base for the operational web apps like the customer activation, vehicle tracking and management and data management, and analytics about ride statistics, user statistics and KPIs. With Pentaho Report Designer they created the invoice template and with Pentaho dashboards they visualize the data, f.e. to discover usage peaks (like in the summer). This also includes a cool map showing the scooters currently in use or parked and allows decisions about locations where the placement of a scooter makes most sense.
For Balázs, the benefits of Pentaho are:
- Fast development of data handling processes (easy to debug, talks to everything)
- Fast development of dashboards and „web applications“ (standard open source technologies, easy to extend)
- More than just a BI platform!
For SCO2T’s CEO, the advantages of Pentaho are:
- Compared to other companies: fast development of new features, fast integration of change requests
- easy to use, good user interaction
- data export and visualization
- Disadvantage: noticeably slow performance compared to programmed (PHP) pages
As weak points of Pentaho Balázs mentioned:
- Data Integration:
Startup messages not controlled by log level
Slow startup - BI Server:
Partially slow
Missing documentation on CDF (one relys on community and blogs)
Behavour changes between versions (map markers)
Balázs then recommended some technologies he likes using,
f.e. PostgreSQL with PostGIS, PostgREST (automatic web API creation without programming) and Traccar for multi-vendor device tracking software.
Pentaho 8 Reporting for Java Developers

Alfresco users know him well: Francesco Corti is Product Evangelist for the document management platform and very active in the Alfresco community. So, what is he doing at PCM?! Some of you might remember the book „Pentaho Reporting 3.5“, one of the undispensable items Pentaho developers used to have on their desks. This year, Francesco has updated the book and presented it to the Pentaho community. In the book, developers will discover how easy it is to embed Pentaho Reporting into their Java projects or use it as a standalone reporting platform.
The book is written for two types of professionals and students: Information Technologists with a basic knowledge of Databases and Java Developers with a medium seniority. The content is primarily written to cover the technical topics about environments, best practices and source code, to enable the reader to assemble the best reports and use them into an existing Java application.

All the topics are faced using a “learning by example” description, thank to a public repository available on GitHub. The repository contains dozens of examples explained one by one in the book, to cover the most valuable features
and best practices in developing reports using the standalone designer (called Pentaho Report Designer) or programmatically (through fully featured Maven projects developed using Java).
Automatic Machine Learning (AutoML) and Pentaho help to leverage Machine Learning

A very hot topic was presented by Caio Moreno de Souza: AutoML and Machine Learning. The demand for machine learning experts has outpaced the supply. To address this gap, there have been big strides in the development of user-friendly machine learning software that can be used by non-experts and experts alike. AutoML software can be used for automating a large part of the machine learning workflow, which includes automatic training and tuning of many models within a user-specified time-limit.
In his presentation and live demo Caio demonstrated the process of how AutoML open source tools together with Pentaho can help customers to save time in the process of
creating a model and deploying it into production. The tools used in the live demo were PDI, H2O AutoML, and AutoWeka. Besides AutoML, Caio is also working on a project called MinervaAutoML.
ETL-Pilot (Data Load Supervision Dashboard)

The next talk was about the monitoring of data loading processes. In the beginning, Alain Debecker, BI Senior Consultant at Team-Partners Switzerland, asked the audience the following questions:
- What to do when your ETL moves into professional production?
- When you coordinate a bunch of automatic data load running every now and again on various crontab or carte servers?
- When you need to monitor a migration done by distant developers?
- When you are responsible for the data to be there, on time and correct?
Why, in those case, not use the logging system which is shipped with your PDI? The PDI logging system records all the details about every thing that is happening during execution and stores it in a database table.
As it is sitting in a database, it is easily displayed on a dynamic report or on a web page so that you can follow the load in real-time. At the same time, you will see the load of all ETLs running and recording on the same logging database, wether launched by an automatic scheduler or by other developers. It is also pretty easy to go back in history and look if and when something went wrong. Additionally you can program and schedule a morning mail to yourself in order to know if your data server is up and running with the correct data, even before you reach the office. Enabling PDI loggings is a 7 clicks operation explained here, with best practices here.
All you need to monitor for the ETL automated loads is the logging of the transformations. As a matter of facts, during consultancies for customers with heavily automated ETL systems, we discovered that in fine what you are after is how much data per table is loaded, and this data is always loaded by a transformation. To log at job level is useful during coding, synchronization and optimization but it does not give you the helicopter view you need to quickly review the nightly ETL. And if you have some authority on the developers, then try to simplify your life with a simple a convention: as far as possible, each transformation loads only one table and has the same name as this table.
On github, you’ll find a JSP that displays continuously the logging table on a web page. Slip the loggings.jsp in a tomcat/webapps/etl folder. Then type yourhost:8080/etl/loggings.jsp in your browser. We made sure to use the PDI defaults and no jar libraries so that it should work as soon as the config.properties points to your database connection.
The information displayed was selected after numerous trials and errors. They are, for each transformation the date of the run, the state (running, finished,…), the duration, the number of record written or updated and the number of errors. The transformation name is a link redirecting to the recent history load so that you can immediately see if the last number of output records is suspicious and if load time is increasing. And selecting the date of the run sends you to the detailed log, which you can follow real-time.
You’ll also find a MorningMail.ktr which sends you a small report of the previous 24h loads and makes a little bit of clean up in the historical data. Schedule it on your crontab server for a time which is convenient to you, for example on your smartphone on the way to the office.
The graph.jsp is a work-in-progress piece of code, that will eventually replace the history log by a more graphical view. Watch for the updates and, in the meanwhile, send your feedback to Alain. So much can be done, and it is so much more productive to be driven by the users‘ needs on that respect.
The next step is to enable stop and restart your ETL from the logging display page. We are blocked by two requests still open in the Vantara-Pentaho jira:
- PDI-16549 to record the transformation path instead of the transformation name. If the name is enough to see which and when a transformation did not performed its job correctly, you definitely need to put the hands on the actual ktr to restart it, hence the need of the full path.
- PDI-16550 to record the parameters of the transformation at the time of the run so that you can restart it in the same conditions. As sometimes the parameter values are given by an orchestrating job, so to guess them on the next day is no always an easy task.
In conclusion, setup your PDI logging, install the ETL-pilot on your server, watch in real-time what you and your colleagues are loading, enjoy its MIT license to
make it suits to your own needs. And when you have a few month of data tell Alain what you think about the graphs, and do not forget to help the community by voting for the JIRA-16549 and the JIRA-16550 as massively as possible.
Pentaho Standardised Git Repository Setup

In the next talk, Diethard Steiner emphasized the importance standards: In big projects with multiple teams and even small projects, „standards are key“. Make everything as simple as possible and keep it consistent. The „Pentaho Standardised Git Repo Setup“ utility tries to combine these two concepts and creates a basic git structure. A version control system like Git is essential to every setup.
This implementation does not require an additional packages (only relies on bash which is usually installed by default). It is one method of putting all the theory outline into place. The main goal is to give teams a starter package in the form of a predefined Git folder structures with checks in place that a minimum set up rules is followed.
The code is available on Diethard’s webpage.
The main functionality is implemented, but there are further aspects like CI that are at very early stages. Currently this project is in the early alpha stage so Diethard appreciate any feedback.
Continuous integration with PDI

Slawomir Chodnicki gave an overview of the benefits of automated testing, defined different types
of ETL tests and showcased techniques for implementing an ETL test suite. More information is available in the articles Testing strategies for data integration and Continuous integration testing for Pentaho Kettle projects.
WebSpoon and SpoonGit for Pentaho PDI
Hiromu Hota presented exciting stuff: webSpoon and SpoonGit for Pentaho PDI. His talk got standing ovations as SpoonGit allows you to manage versions of local Kettle files without leaving Spoon. In addition to Git, Subversion is also supported. Hiromu was kind enough to immediately tweet his slides – thank you Hiromu!

Pentaho CDE NewMapComponent
Creating richer visualizations sometimes means including maps on the dashboards as well. The CDE NewMapComponent is a very flexible component that allows the user/developer to add a map and show geo-referenced data on top of it. There are many features and customizations that one can use but some of those features and configurations are not understood or even unknown. In his presentation, Kleyson Rios explained the proper use of the component, how to customize it and how to deal with its more complex configurations.
