
Auf dem diesjährigen Pentaho User Meeting hatte ich wieder das Vergnügen, den abschließenden Vortrag zu halten. Dieses Mal ging es um die Auswertung von Internet-of-Things-Daten. Als Beispiel hatte ich ein aktuelles Thema gewählt: die Analyse von Feinstaubdaten. Der Usecase zeigt sehr gut, was bei IoT Analytics wichtig ist und worauf man achten sollte.
Ende Januar fand in Stuttgart der Feinstaub Hackathon statt, an dem auch meine Kollegen Dr. David James und Dirk Rönsch teilnahmen. Stuttgart gehört zu den am stärksten von der Feinstaubthematik betroffenen Kommunen Deutschlands. Der Hackathon wurde von der Stuttgarter Zeitung organisiert und sollte jedem die Möglichkeit bieten, über Luftqualität zu diskutieren, Ideen auszutauschen und Prototypen für die Messung der Luftqualität zu entwickeln.
Die Daten über die Luftqualität stammen von Bürgern, die diese frei zur Verfügung stellen. Rund um das Thema Luftqualität hat sich eine richtige Community entwickelt – jeder kann teilnehmen und selbst Messwerte zum Netzwerk beitragen. Dazu genügt es, sich zwei Sensoren zu kaufen und die bereitgestellte Software aufzuspielen – schon ist man ein Mitglied des Netzwerks und bereichert den Datenpool um weitere Messwerte. Die gesammelten Daten lassen sich alle 15 Minuten über eine API als JSON abrufen oder als Archiv-Dateien herunterladen, die bis ins Jahr 2015 zurückreichen. Im Nachgang an den Feinstaub Hackathon habe ich mich etwas intensiver mit den Daten befasst und auf deren Grundlage die folgenden fünf Erkenntnisse für die Auswertung von Sensorendaten entwickelt.
Was ist Feinstaub?
Obwohl das Thema Feinstaub aktuell omnipräsent in den Medien ist, möchte ich dennoch zu Beginn ein paar kurze Informationen einwerfen. Feinstaub wird meist als PM10 oder als PM2.5 bezeichnet, wobei das PM für Particulate Matter (Englisch für Feinstaub) und die 10 bzw. die 2.5 für die Staubpartikelgröße in Mikrometer steht. Feinstaub wird vor allem durch menschliches Handeln verursacht, z.B. durch:
- Emissionen aus Kraftfahrzeugen
- Strom- und Wärmeerzeugung
- Öfen und Heizungen
- aber auch: natürliche Quellen, z.B. Staubaufwirbelung von Böden oder Pollenflug
Wie funktioniert ein Sensor?
Ein Sensor ist eine Komponente, die eine gemessene physikalische Größe in ein analoges elektrisches Signal umwandelt. Dies kann zum Beispiel sein:
- Beschleunigung
- Druck
- Strahlung
- Temperatur
Mittels speziellen Wandlern entsteht ein elektrisches Signal, dass vom Menschen gelesen bzw. interpretiert werden kann. Für die Weiterverarbeitung senden die Sensoren die gemessenen Werte meist an einen nahegelegenen Empfänger per Bluetooth oder per Wlan direkt in die „Cloud“.
Jetzt also zu den Dingen, die man bei der Analyse von Sensoren- und anderen Maschinendaten beachten sollte:
1. Täuschende Schlichtheit
„Der erste Eindruck der Daten kann trügen“
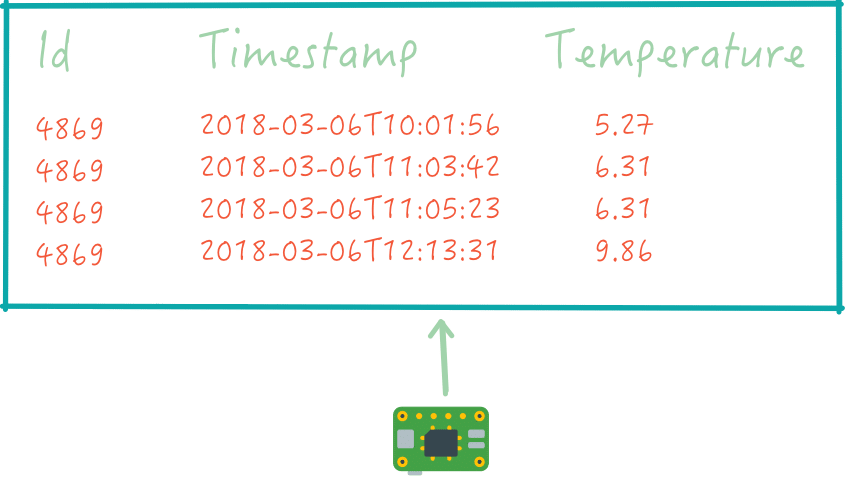
Schauen wir uns zunächst die Daten des Sensors an, der die Temperatur misst. Das Ganze sieht zunächst simpel aus: Pro Zeile gibt es einen Zeitstempel und den dazugehörigen Messwert (= die Temperatur). Um die Daten aber richtig interpretieren und mit anderen Sensoren aus dem Netzwerk vergleichen zu können, fehlen weitere Informationen, die nicht direkt von diesem Sensor stammen.
Eine dieser fehlenden Informationen wäre zum Beispiel die Position des Sensors: Neben dem Längen- und Breitengrad ist es interessant zu wissen, ob der Sensor drinnen oder draußen steht bzw. ob er direkter Sonneneinstrahlung ausgesetzt ist oder nicht. Diese Informationen werden benötigt, damit der Temperaturwert besser interpretiert werden kann: die exakte Position des Sensors wirkt sich letztendlich auch auf die Messwerte aus.
Erkenntnis: Erst durch die Kombination von mehreren Datenquellen (Data Blending) entsteht ein Datensatz, der sich interpretieren und auswerten lässt. Die reinen Sensorendaten haben meist nur wenig Informationsgehalt. Es ist außerdem ratsam, sich in die Dokumentation des Sensors einzulesen, da nicht immer sprechende Spaltennamen für die einzelne Messwerte vergeben werden.
2. Sinnvolle Frequenz bestimmen
„Wie oft messe ich und welche Daten speichere ich?“
Im Gegensatz zu klassischen OLTP-Systemen (Online Transaction Processing) ergibt sich bei Sensordaten die Möglichkeit, die zu speichernde Datenmenge ohne Informationsverlust zu komprimieren. Das erkläre ich an einem Beispiel genauer:
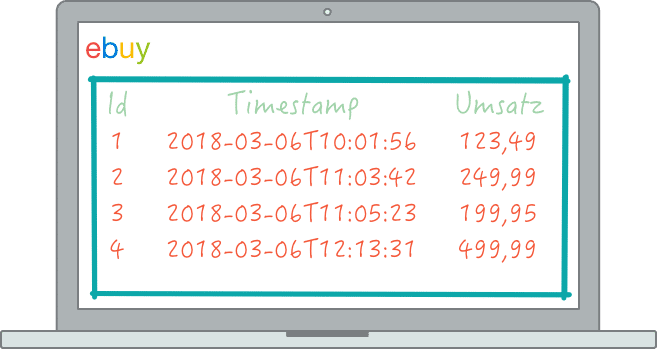
Das fiktive Unternehmen ebuy betreibt einen Online-Marktplatz und hat zu vier verschiedenen Kunden den Umsatz mit Zeitstempel erfasst und in einer Datenbank gespeichert. Im Laufe der weiteren Verarbeitung (zum Zweck der Analyse) müssten wir diese vier Einträge extrahieren, transformieren und wieder abspeichern, d.h. wir haben prinzipiell keine Möglichkeit, die Datenmenge ohne Informationsverlust zu komprimieren. Dadurch, dass die einzelnen Kundeneinträge unabhängig voneinander sind (dazu mehr unter Punkt 4), kann ein fehlender Eintrag nicht durch die anderen Einträge wiederhergestellt werden. Das bedeutet konkret: Speichert man die Zeile mit der Id 3 nicht ab, so kann diese Information nicht durch die verbleibenden Einträge 1, 2 und 4 rekonstruiert werden.
Anders verhält es sich mit Sensordaten. Der Temperatursensor lässt sich derart konfigurieren, dass er alle 5 Sekunden einen Wert erfasst und speichert bzw. per Bluetooth an einen Empfänger oder über Wlan in die Cloud sendet. Als Resultat werden die Daten dann wie folgt angeliefert:

Der Temperatursensor liefert uns also alle 5 Sekunden einen neuen Messwert. Wenn wir davon ausgehen, dass es sich um die Außentemperatur handelt, die erfasst wird, muss man sich an dieser Stelle die folgenden Fragen stellen:
- Ist es sinnvoll, alle 5 Sekunden einen Temperaturwert zu messen?
- Ist es sinnvoll, alle 5 Sekunden einen Temperaturwert zu speichern?
Zu häufiges Messen verringert die Lebensdauer des Sensors. Deshalb kann es ratsam sein, das Intervall zwischen zwei Messpunkten entsprechend anzupassen. Das richtige Intervall zu bestimmen ist jedoch keinesfalls trivial: ist es zu hoch gewählt, dann können eventuell interessante Beobachtungen verloren gehen, da sie nicht erfasst wurden. Wählt man hingegen ein sehr kleines Intervall, so verkürzt dies die Lebensdauer des Sensors und eventuell interessante Beobachtungen lassen sich in der Masse der Daten schwieriger identifizieren.
Oftmals hat man als Data Engineer nicht die Möglichkeit, direkt Einfluss auf den Sensor und dessen Messintervalle zu nehmen und muss daher die gelieferten Messdaten als gegeben hinnehmen. Man hat aber die Möglichkeit, die Verarbeitungszeit und die zu speichernde Datenmenge zu beeinflussen – ohne Informationsverlust! Eine einfache Komprimierung könnte so aussehen, dass lediglich dann ein Wert vom Empfänger gespeichert wird, wenn sich der Messwert geändert hat – ansonsten wird der Messwert verworfen.
Mit dem Hintergrundwissen, dass lediglich das Delta abgespeichert wird, können die verworfenen Messwerte mit Hilfe des Messintervalls rekonstruiert werden. Der Facebook Inkubator beschreibt in seinem Paper Gorilla: A Fast, Scalable, In-Memory Time Series Database, wie so eine Komprimierung aussehen kann. Durch den beschriebenen Kompressionsalgorithmus lässt sich die zu speichernde Datenmenge um bis zu 90% reduzieren. Das spart im Endeffekt nicht nur Speicher, sondern verkürzt auch die Verarbeitungszeit. Dadurch sind Analysen in Echtzeit erst möglich.
3. Zuverlässigkeit
„Fehlerhafte und fehlende Messwerte müssen im Analyseprozess identifiziert werden“
Ein Sensor ist meist nicht selbst in der Lage, fehlerhafte Messwerte zu erkennen und entsprechende Gegenmaßnahmen einzuleiten. Das liegt u.a. an der (meist) geringen Rechenkapazität des Sensors, die für umfangreiche Analyseprozesse zur Identifizierung fehlerhafter Werte schlicht nicht ausreicht. Diese Aufgabe muss der Data Engineer während des Analyseprozesses übernehmen.
Auch kann man nicht immer davon ausgehen, dass die Sensoren oder der Empfänger, der die Daten entgegennimmt, zuverlässig funktionieren. Im folgenden Beispiel wollen wir versuchen, fehlerhafte und fehlende Messwerte zu identifizieren und passende Lösungen zu erarbeiten.

In der Abbildung markiert der Pfeil mit der Nummer 1 eine Lücke von mehreren Sekunden im Zeitverlauf. Ursache für den Aussetzer könnte ein nicht erreichbarer Empfänger sein, d.h. der Sensor hat zwar einen Wert zu diesem Zeitpunkt gemessen, durch eine unterbrochene Verbindung zum Empfänger ist dieser aber verloren gegangen. Ein anderer Grund könnte ein Qualitätsproblem des Sensors selbst sein, d.h. der Sensor hat zu diesem Zeitpunkt wirklich keinen Messwert erfasst. Eine kurzfristige Lösung wäre, anhand der vorher (und eventuell nachher) gemessenen Werte einen Durchschnittswert zu ermitteln und mit diesem die Lücke zu füllen. Anstatt des Durchschnittswerts ist auch die Entwicklung (komplexer) Data Science-Modelle denkbar. Wenn sich die Lücken häufen, sollte man darüber nachdenken, den Sensor auszutauschen bzw. die Verbindung zum Empfänger näher zu untersuchen.
Zurück zu unserer Abbildung: Der Pfeil mit der Nummer 2 markiert zwei Ausreißer im Temperaturverlauf. Die Temperaturmesswerte sind innerhalb von einer Sekunde um das drei- bzw. vierfache gestiegen und danach wieder gefallen. Es gilt nun zu untersuchen, ob dies ein Fehler des Sensors war, der zu diesen Zeitpunkten falsche Werte erfasst hat, oder aber ob es sich um einen validen Messwert handelt. Ausreißer dürfen daher nicht per se als falsch interpretiert werden. Eine Strategie könnte sein, die Ausreißer zunächst zu filtern und anschließend genauer unter die Lupe zu nehmen. Untersuchungsgegenstand ist meist das Finden von Gemeinsamkeiten, um in Zukunft das Eintreten von Ausreißern „vorhersagen“ zu können.
Der Pfeil mit der Nummer 3 markiert eine Lücke von mehreren Sekunden und einen Temperaturanstieg von zwei Grad Celsius unmittelbar danach. Um das eingetretene Szenario zu verstehen, sind auch hier wieder Hintergrundinformationen notwendig. Da der Sensor in unserem Beispiel die Außentemperatur misst, könnte man sich fragen:
- Kann die Außentemperatur innerhalb von 10 Sekunden um 2° ansteigen?
- Gibt es einen Zusammenhang zwischen der Lücke und dem Temperaturanstieg?
Eine mögliche Erklärung wäre, dass jemand den Sensor von drinnen nach draußen gestellt hat und dieser nun direkter Sonneneinstrahlung ausgesetzt ist. Man sollte sich daher weitere Informationen über die Situation besorgen, bevor man handelt.
4. Nicht alle Daten sind gleich
4.1. Cross-Sectional Data
Nicht alle Daten lassen sich gleich erheben und auswerten. Grob unterscheidet man zwischen Cross-Sectional und Time-Series Data. Bei Cross-Sectional Data handelt es sich um Daten, die durch die Beobachtung vieler Objekte zum gleichen Zeitpunkt erhoben wurden. Diese Objekte können sein:
- Einzelpersonen
- Firmen
- Filialen
- Länder
Die Analyse besteht in der Regel darin, die Unterschiede zwischen den Objekten zu vergleichen. Sie eignet sich daher nicht für die Auswertung von Feinstaubdaten, wo es ja auf ihre Entwicklung im Zeitverlauf ankommt.
Ich nehme daher ein anderes Beispiel: Wenn wir die Werte für Fettleibigkeit in einer Population bestimmen wollen, können wir 1.000 Personen via Zufallsprinzip aus dieser Bevölkerung extrahieren, deren Gewicht und Größe messen und berechnen, wie viel Prozent der Personen als fettleibig eingestuft werden können. Die Auswahl an Personen lässt sich zufällig treffen, da in der Regel keine Abhängigkeiten zwischen den einzelnen Beobachtungen existieren. Zu beachten ist aber, dass die Analyse lediglich eine Momentaufnahme dieser Population, d.h. zu einem bestimmten Zeitpunkt, darstellt. Wir wissen nicht, ob die Fettleibigkeit zu- oder abgenommen hat, d.h. es lassen sich keine Trends feststellen.
4.2. Zeitreihendaten
Bei Zeitreihendaten (time-series data) handelt es sich um eine Sammlung von Beobachtungen zu einem einzelnen Objekt zu verschiedenen Zeitpunkten. In der Regel sind die Zeitabstände gleichmäßig verteilt, z.B. alle 30 Minuten oder immer am ersten Tag des Monats. Ausnahmen bestätigen auch hier die Regel: die Messungen können natürlich auch unregelmäßig erfolgen. Unser Feinstaubbeispiel fällt also in diese Kategorie.
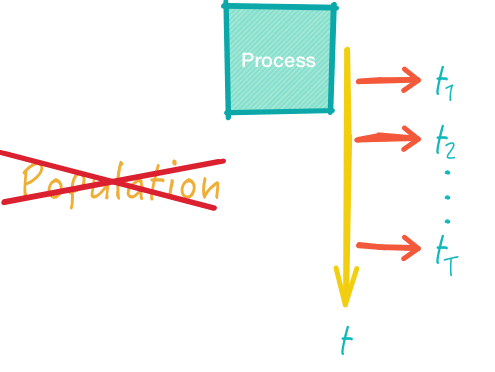
Die Abbildung zeigt gemessene Temperaturwerte (t1, t2, usw.). Sie stammen allesamt vom selben Prozess. Da sich die Temperatur im Zeitverlauf meistens verändert, können die Messwerte nicht unabhängig voneinander betrachtet werden. Im Sommer erreicht die Temperatur gegen Mittag bzw. Nachmittag meist ihren höchsten Wert und sinkt danach wieder. Anhand der zuvor gemessen Werte können wir somit einen Trend für den Temperaturanstieg und -abstieg erkennen und wie stark dieser ausfällt. Das bedeutet, dass es keinen Sinn macht, sich zufällige Werte herauszunehmen und diese miteinander zu vergleichen wie wir es bei Cross-Sectional Data getan haben – die Ansätze unterscheiden sich grundlegend voneinander.
Dadurch dass wir nun ein einzelnes Objekt über einen längeren Zeitraum beobachten, können wir im Gegensatz zu Cross-Sectional Data Trends und saisonale Effekte erkennen. Bei saisonalen Effekten handelt es sich um Entwicklungen, die sich in gewissen Abständen selbst wiederholen. Deutlich wird das, wenn wir den Arbeitsmarkt betrachten: Im Winter bieten die Landwirtschaft und das Baugewerbe weniger Arbeitsplätze als im Sommer, da die Witterungslage Einfluss auf die Beschäftigungslage hat. Man beobachtet daher meist, dass die Arbeitslosigkeit im Sommer sinkt und im Winter ansteigt.
Möchte man nun ein Modell erstellen, mit dessen Hilfe eine mögliche Prognose der zukünftigen Entwicklung getroffen werden soll, gilt es einiges zu beachten:
- Aus dem Zeitstempel lassen sich viele Kennzahlen (im Data Science-Umfeld spricht man auch von Features) ableiten, die für ein Prognosemodell genutzt werden können. Neben offensichtlichen Kennzahlen wie:
- Jahr, Monat, Tag, Stunde, Minute und Sekunde
- Quartal, Kalenderwoche, …
sind vor allem die nicht so offensichtlichen Kennzahlen interessant, z.B.:
- Frequenz, d.h. die Zeit, die zwischen zwei Beobachtungen verstrichen ist. Daraus lässt sich ableiten, ob die Daten in gleichen Zeitabständen gemessen wurden oder nicht.
- Des Weiteren kann nach Mustern gesucht werden, z.B. ob eine Regelmäßigkeit existiert, mit der fehlerhafte Werte auftreten.
Bei all dem darf man eines aber nicht außer Acht lassen: Hat man eine Gesetzmäßigkeit bzw. ein Muster gefunden, mit dem fehlerhafte oder fehlende Werte identifiziert werden können, so kann in Zukunft darauf reagiert werden. Mit anderen Worten, das gefundene Muster hat für die Zukunft keine Bedeutung mehr! So führt der Ersatz fehlerhafter Sensoren durch neue Geräte zu neuen Messergebnissen. Bei der Erstellung des Prognosemodells handelt es sich also um einen fortlaufenden, andauernden Prozess.
5. Wenn Predictive Analytics, dann Vorarbeiten! (Zeitseriendaten)
Wer seine Daten auswerten kann, will meistens mehr als nur historische Daten zu analysieren. Predictive Analytics sind Verfahren, mit denen auf Grundlage von Daten aus der Vergangenheit Vorhersagen über deren zukünftige Entwicklung getroffen werden können. Zum Einsatz kommen Techniken aus den Bereichen Statistik und Maschinenlernen. Ziel ist es, ein aussagekräftiges Modell für die Berechnung von Vorhersagen zu entwickeln. Dafür sind aber ein paar Vorarbeiten nötig.
Um das Modell erstellen zu können, benötigt man Beobachtungswerte eines Prozesses über einen möglichst langen Zeitraum, also die erwähnten Zeitreihendaten (time-series data). Sensordaten sind grundsätzlich gut geeignet, um Techniken aus dem Predictive Analytics-Umfeld anzuwenden, da sie zum einen Informationen über einen Prozess über einen längeren Zeitraum bereitstellen und zum anderen (je nach Messintervall) in großer Menge vorliegen.
Die in der Praxis am häufigsten angewandten Verfahren werden mit dem Begriff „überwachtes Lernen“ überschrieben. Dieses Verfahren kann man sich so vorstellen: Ein Lehrer versucht seinem Schüler die Addition im Zahlenraum bis 100 beizubringen. Dazu nennt er ihm zwei Zahlen und dieser teilt ihm anschließend das seiner Meinung nach richtige Ergebnis mit. Der Lehrer ermittelt nun seinerseits das richtige Ergebnis und sagt es dem Schüler. Dieser kann nun anhand seines eigenen Ergebnisses und dem des Lehrers überprüfen, ob sein Vorgehen richtig oder falsch war. Ziel ist es also, aus einem gegebenen Input (hier die zwei Zahlen) den richtigen Output (hier das Ergebnis der Addition) abzuleiten. Dafür versucht der Schüler eine Gesetzmäßigkeit zu entwickeln, die sich auf den Sachverhalt anwenden lässt.
Der „allwissende“ Lehrer ist in der Praxis meist ein Experte auf seinem Gebiet oder man nutzt z.B. physikalische Gesetze, um das Ergebnis zu verifizieren. Möchte man nun überwachtes Lernen auf unsere Sensordaten anwenden, ergibt sich zunächst ein Problem:
| Timestamp | Messwert |
|---|---|
| 2018-06-03T10:00:00 | 10 |
| 2018-06-03T11:00:00 | 14 |
| 2018-06-03T12:00:00 | 20 |
Möchten wir den Messwert 14 vorhersagen, steht uns nur der Timestamp zur Verfügung, also 2018-06-03T11:00:00. Das ist der Tatsache geschuldet, dass die Verfahren zeilenweise arbeiten. Zwar lassen sich aus dem Timestamp auch einige interessante Informationen ableiten, wir haben aber bereits gelernt, dass es wenig Sinn macht, Messwerte isoliert zu betrachten und wollen daher mindestens auch den vorher gemessenen Wert (= 10) mit in Betracht ziehen. Um überwachtes Lernen anwenden zu können, müssen wir nun unsere Daten zuvor entsprechend anpassen. Dazu nutzen wir eine Technik, die sich Sliding Window nennt. Aus der Ausgangstabelle wird nun folgende Tabelle:
| Timestamp t-1 | Messwert t-1 | Messwert |
|---|---|---|
| null | null | 10 |
| 2018-06-03T10:00:00 | 10 | 14 |
| 2018-06-03T11:00:00 | 14 | 20 |
Diese Tabelle können wir jetzt für überwachtes Lernen nutzen. Neben der Spalte Messwert, die den vorherzusagenden Wert enthält, existieren ebenfalls der zuvor gemessene Wert (Messwert t-1) und dessen Timestamp (Timestamp t-1) als Spalte. Dadurch, dass diese Informationen nun in einer Zeile stehen, lassen sich Verfahren aus dem Bereich überwachtes Lernen anwenden, die sich in der Praxis an anderer Stelle bereits bewährt haben.
Fazit
IoT-Daten wie in unserem Feinstaubbeispiel haben das Potential, unsere Lebensweise zu verändern, wie es in Stuttgart beispielsweise der Fall ist. Durch die hohe Feinstaubbelastung ist die Stadt gezwungen, Lösungen gegen einen Anstieg der Luftbelastung zu erarbeiten. IoT-Analysen können dabei unterstützen, besonders betroffene Gebiete zu identifizieren und zu überprüfen, wie wirksam die eingeleiteten Maßnahmen sind. Wie dieser Artikel gezeigt hat, handelt es sich bei IoT Analytics aber keineswegs um eine Plug-and-Play-Technologie, sondern um ein komplexes Thema, bei dem eine Reihe von Besonderheiten beachtet werden muss. Die Implementierung einer IoT Analyseanwendung setzt deshalb ein fundiertes Konzept und einen detaillierten Umsetzungsplan voraus.
Diese Artikel könnten Sie auch interessieren: