
Als wir im Herbst letzten Jahres mit der Vorbereitung des Pentaho User Meetings 2020 begannen, hätten wir uns nicht träumen lassen, dass es erst 12 Monate später stattfinden würde. Und das auch nur virtuell. Nachdem sich die Ereignisse im Frühjahr überschlugen, die halbe Arbeitswelt ins Home Office wechselte und niemand wusste, wie es weitergehen würde, sind wir aber einfach nur froh, die Krise gesund überstanden zu haben. Inzwischen sind Online-Meetings normaler Bestandteil unseres Alltags – also warum nicht auch alle Pentaho-Anwender virtuell zusammenbringen?
Und so sah es auch die Community: für die siebte (und erste Online-) Ausgabe des Pentaho User Meetings haben sich 115 Teilnehmer angemeldet. Wie wichtig Datenmanagement und Datenintegration sind, hat sich schon vor der Pandemie gezeigt. Aber vielen Organisationen haben erst die letzten Monate wirklich die Vorteile der Digitalisierung vor Augen geführt. Plattformen für die Zusammenführung, Aufbereitung und Auswertung von Daten sind einer der Schlüssel für die Bewältigung der Herausforderungen des digitalen Zeitalters. Deshalb ist es auch nur folgerichtig, dass zum Auftakt des Anwendertreffens Jens Bleuel eine solche Plattform vorstellt, nämlich Lumada von Hitachi Vantara.
Die alte und die neue Pentaho-Welt: Pentaho und Lumada
Seit dem Kauf von Pentaho vor drei Jahren hat Hitachi Vantara den Fokus und die Zusammensetzung der Plattform ständig weiterentwickelt. Die Plattform versucht, alle Schritte des Datenlebenszyklus abzudecken, von der Integration verschiedener Datenquellen bis zur Analyse von Bewegtfilm- und IoT-Daten unter Beachtung von DSGVO-Regelungen und ihrer Bereitstellung in Self-Service-Anwendungen.
Die Vision von Hitachi für die Analytics-Komponenten von Pentaho zielt darauf ab, die Herausforderungen aus dem KI- und ML-Bereich abzudecken, mit denen Data Engineers und Data Scientists täglich zu tun haben. Ziel ist es, die verschiedenen Datenanwender vom Data Engineer über Data Stewards bis zu den Analysten, Data Scientists und Fachanwendern zu unterstützen. Während das Pentaho schon immer gemacht hat, kann es dank der Integration in Lumada nun erstmals von Edge-to-Cloud bis Multi-Cloud-Szenarien überall laufen. Der Endanwender aber merkt davon nichts. Gesteuert werden alle Prozesse zentral über die Lumada-Plattform.
Die Roadmap für Pentaho Analytics:
- Moderneres Dashboarding
- aktuelle und erweiterbare Library für Visualisierungen
- Erstellung von Rich Applications
- ML-Entwicklung und Deployment
Als Vision für PDI (Pentaho Data Integration) zählte Jens ein zentrales Scheduling, die Ausführung und das Monitoring von Datenströmen, Kubernetes- und container-basierte Ausführung, Zugangskontrollen für Datenströme, GIT-basiertes Repository für Datenströme und einen webbasierten Datenfluss-Designer auf.
Das spiegelt sich auch in der Roadmap wieder, auf der u.a. eine kontinuierliche PDI-Weiterentwicklung stehen sowie neues Deployment und Ausführung, ein zentrales Monitoring und eine Data Catalog-Integration.
Was bedeutet das nun für Pentaho-Kunden?
Laut Jens ist und bleibt Pentaho ein kritischer und essentieller Teil der Lumada Plattform. Die bestehende Funktionalität von Pentaho wird im Moment umgebaut und modernisiert, um sie an die Cloud-Anforderungen anzupassen und noch mehr Self-Service-Zugänge zu den Daten anzubieten – das alles vom Web aus ohne die früher nötige Installation beim Anwender.
Ablösung von Inubit durch Pentaho

Ein echter Pentaho Power User ist Jens Junker, der beim Gashändler VNG Handel & Vertrieb im ETL- und Pentaho-Projekt arbeitet. Jens war bereits auf dem Pentaho User Meeting 2019 zu Gast, wo er die Abbildung von Datenprozessen für Compliance-Anforderungen durch PDI vorstellte. Eines der größten Teilprojekte war dabei die Prozess-Migration von Inubit nach Pentaho. VNG hat PDI seit 2012 im Einsatz und damit diverse Softwarelösungen abgelöst, u.a. OWB, PowerMart sowie auch Inubit.
Inubit wurde 2014 eingeführt für das Business Prozess Management und die Prozessmodellierung. Die ganze Logik, die in Pentaho in Steps enthalten ist, steckt bei Inubit in XSLT Konnektoren. Das ganze System basiert darauf, dass eine XML-Nachricht eingeht, transformiert und dann weitergereicht wird, es handelt sich also um ein nachrichtenbasiertes System. Das unübersichtliche XML-Format ist aber auch ein Nachteil von Inubit. Der visuelle Ansatz von Pentaho dagegen ist viel verständlicher und erfordert keinerlei XML-Kenntnisse.
Ziel der Ablösung von Inubit war es, Wartungs- und Supportkosten zu reduzieren sowie den Betriebsaufwand zu verringern. Das Projekt war durch die sieben Quellsysteme und neun Zielsysteme sowie 12 zu migrierende Prozesse teils sehr komplex. Zu den Businessprozessen gehörten, Settlements, das regulatorische Reporting, Lastgang, Prognosen sowie die Steuerung von externen Prozessen. Dank eines Frameworks, das von it-novum entwickelt wurde, konnten Prozesse einfach in PDI abgebildet werden.
Während des Projekts sah sich Jens´ Team mit einigen Herausforderungen konfrontiert. Neben der aus der Lockdown folgenden Home Office-Pflicht wurden nach dem Absturz des Ölpreises Mitarbeiter in andere interne Projekte abgezogen. Am meisten Kopfzerbrechen bereiteten jedoch die Laufzeiten von Pentaho. Da in einige Prozesse Endanwender involviert wurden, galten für die Laufzeiten auf einmal andere Anforderungen. Nach der Migration auf eine neuere Pentaho-Version konnte die Laufzeit von 25 auf 6 Sekunden gesenkt werden. Grund war, dass in Version 8.3.0.1 im „Replace in string“ Step „Yes/No“ für „use RegEx“ vertauscht war.
Momentan ist das Team noch damit beschäftigt, alle Funktionen von Inubit in Pentaho zu übertragen. Dann soll die Infrastruktur dahingehend überprüft werden, ob PostgreSQL und Linux besser zu Pentaho passen als die Kombination Oracle und Windows. Geplant ist, die Migration bis Ende des Jahres abzuschließen, die Pentaho-Infrastruktur umzubauen und Pentaho auf Version 9.X zu aktualisieren. Auf die Frage eines Teilnehmers hin nach Performance-Unterschieden zwischen Inubit und Pentaho stellte Jens klar, dass Pentaho mit dem XML-Dateien von Inubit sehr gut umgehen konnte und einen klaren Zeitvorteil bei der Übertragung von großen Datenmengen brachte (vorher mehrere Stunden, mit Pentaho ca. 20 Minuten).
Die neue SAP-Welt
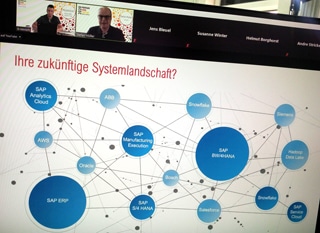
Früher war die Welt der SAP-Benutzer einfach: SAP BW und SAP ERP waren im Einsatz, liefen stabil und es gab mehr oder weniger flexible Integrationen. Seitdem haben sich aber auch im SAP-Universum die Dinge geändert. Viele neue Datenquellen sind dazugekommen, die meisten davon außerhalb der SAP-Welt. Es müssen viel mehr Geschäftskennzahlen als früher ausgewertet werden, wofür Informationen aus anderen Systemen nötig sind, die teils auch in der Cloud liegen.
Liegen Daten in der Cloud, lassen sie sich nicht nur einfach anderen Anwendergruppen wie Business Analysten, Lieferanten oder Kunden zur Verfügung stellen. Sie können auch mit Daten aus weiteren Quellsystemen verschnitten werden, um ganz neue Analysen zu ermöglichen. Durch Pentaho Data Integration lässt sich ein gesamtes Data Warehouse in die Cloud von Snowflake migrieren, einem der momentan am stärksten wachsenden Cloud-Anbieter.
Die Snowflake-Cloud ist interessant für analytics-affine Unternehmen, da ihre Architektur speziell für die Integration und Auswertung von Daten entwickelt wurde. Die Plattform ist neutral gegenüber der Cloud-Infrastruktur und auf AWS und Azure verfügbar. Hostet ein Anwender dort bereits Daten, können diese ohne viel Aufwand in Snowflake geladen werden. Aber auch von On-Premises oder bei komplexeren Datenstrukturen ist das Datenladen sehr effizient, denn beinahe alle klassischen und jüngeren ETL-/ELT-Werkzeuge besitzen einen Konnektor zu Snowflake.
Wie sich SAP-Daten mit Pentaho Data Integration extrem einfach in Snowflake migrieren und danach kontinuierlich beladen lassen, demonstrieren meine Kollegen Philipp Heck und Andreas Kuhn in diesem Video. Dabei kommt PDI zum Einsatz, um die SAP-Daten und die Datenbankstruktur in die Cloud zu laden.
Datenkataloge: entspannt den Datensee befischen

Andreas Kuhn stellte in seinem Vortrag die neue Datenkatalogsoftware von Hitachi Vantara vor, die neben Pentaho einen Bestandteil der Lumada-Plattform darstellt.
Weil das Thema Datenmanagement viel komplizierter geworden ist, werden Datenkataloge immer interessanter für Organisationen. Forrester sagt, dass Analysten 60% ihrer Zeit damit verbringen, Daten zu suchen. Das Thema Data Onboarding funktioniert mittlerweile sehr gut, aber die Datenflut wird immer größer. Das erschwert die eigentliche Datennutzung enorm und der Druck auf IT-Abteilungen nimmt zu, Daten aufzubereiten und zur Verfügung zu stellen. Ziel der IT muss es daher sein, Analysten in die Lage zu versetzen, selbst nach Daten zu suchen und Analysen durchzuführen. Datenkataloge helfen dabei, die mühsam aufgebauten Data Lakes entspannt abzufischen.
Andreas wies darauf hin, dass aus diesem Grund der Begriff des Data Lakes inzwischen anders verwendet wird: er meint das Data Warehouse zusammen mit Hadoop, Clouds und weiteren Data Warehouses im Unternehmen. Das Wissen, das in diesen ganzen Daten liegt, muss zusammengeführt werden, um Wissen daraus zu schöpfen.
Dabei sehen sich Organisationen vor diesen Herausforderungen:
- Wissen, welche Daten vorhanden sind
- Die richtigen Daten schnell finden
- Compliance und Governance-Auflagen erfüllen
- Redundanzen eliminieren
- Prozesse optimieren
Die Lösung ist, alle Daten zu taggen und ihnen dadurch einen Business-Kontext zu geben. Doch wie sollen Data Stewards diese Aufgabe angehen? Bei einigen Tabellen lassen sich Daten noch manuell beschriften. Bei mehreren hundert Datenquellen wird es jedoch notwendig, den Tagging-Prozess zu automatisieren.
Mit dem Kauf des Data Catalog-Anbieters Waterline hat Hitachi Vantara neben Pentaho eine weitere Datenmanagementlösung dem Lumada-Portfolio hinzugefügt. Die Datenkatalogsoftware basiert auf KI- und ML-Technologien und ermöglicht die Automatisierung der manuellen Kategorisierung. Das garantiert Organisationen eine exzellente Katalogqualität, sorgt für eine hohe Anwenderzufriedenheit und macht Kapazitäten für wertschöpfendere Tätigkeiten frei. Durch ML-Technologien lernt die Software bei jeder Nutzung dazu und wird dadurch immer besser.
Der Lumada Data Catalog findet sich in der Lumada-Plattform zwischen Pentaho Data Integration und den Business Analytics Applikationen (Pentaho Analytics).
Geodaten DSGVO-konform auswerten
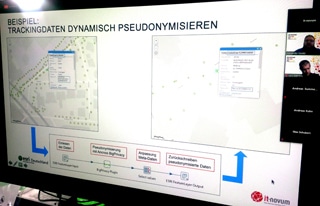
Um Datenschutzthemen bei der Auswertung personengebundener Daten handelte sich der nächste Vortrag, der aus einer spannenden Live-Demo bestand. Lars Behrens von ESRI und Alex Keidel von it-novum erklärten anhand der Demo die Bedeutung der Pseudonymisierung von Bewegungsprofilen und Datenanreicherung.
Die Nutzung und Auswertung von Geodaten wird immer beliebter, da sie zahlreiche Vorteile hat: die in mobilen Endgeräten anfallenden Bewegungsdaten des Geräteinhabers lassen sich auf eine (Land)Karte bringen und können dadurch in Echtzeit aktuelle Positionen von Personen, Fahrzeugen oder anderen beweglichen Objekten darstellen.
Zudem kann man Positionsdaten mit weiteren Informationen anreichern, die bereits in einem Datensystem, z.B. Pentaho Data Warehouse, liegen. Damit kann man weitere Erkenntnisse für Entscheidungsprozesse bereitstellen (ermöglicht wird dies über eine direkte Schnittstelle zwischen GIS und Pentaho).
Wie Lars Behrens von ESRI und Alex Keidel von it-novum betonten, müssen für eine derartige Datennutzung die geltenden Datenschutzanforderungen erfüllt werden. Die Daten müssen deshalb pseudonymisiert werden.
Durch die dynamische Pseudonymisierung von Daten werden die Nutzdaten von den Daten getrennt, die eine natürliche Person direkt oder indirekt identifizieren können. Dabei können weitere Attribute hinzugefügt werden, um später in berechtigten Fällen (z.B. Strafverfolgung) die Person wieder identifizieren zu können. Der Schlüssel, der die Rückverbindung der Nutzdaten mit den personenbezogenen Daten ermöglicht, ist nur einer genau definierten Personengruppe zugänglich.
Derartig pseudonymisierte Geodaten lassen sich überall dort einsetzen, wo die aktuelle Position einen Mehrwert in konkreten Arbeitsprozessen bietet. Dazu gehören die Einsatzplanung bei der Polizei genauso wie die Nachverfolgung von Fahrzeugflotten im Außendienst oder Wartungsarbeiten an Infrastruktureinrichtungen.
Der Einsatz von Pseudonymisierung hilft also, gesetzeskonform Mehrwert aus personenbezogenen Daten zu gewinnen, so auch aus den für verschiedenste Anwendungen immer attraktiver werdenden Geodaten und Bewegungsprofilen.
Zum Abschluss gab Matt Casters einen Ausblick auf aktuelle spannende Technologien im Datenmanagementbereich, Neo4j und Hop. Für weitere Infos zu den beiden Projekten empfehle ich einen Besuch ihrer Webseiten.
Ein herzliches Dankeschön an alle Teilnehmer, vor allem an die 58 Personen, die bis zum Schluss durchhielten 🙂 Dass das erste virtuelle PUM gut ankam, zeigte das überwältigend positive Feedback, das wir am Ende bekamen. Vor allem die Breakout Sessions waren bei vielen Usern auf Interesse gestoßen, da sie nach jedem Vortrag die Möglichkeit eröffneten, dem Referenten in einem eigenen virtuellen Raum Fragen zu stellen und das über die üblichen 10 Minuten für Q&As hinaus. Auch wenn sich der persönliche Kontakt, der das User Meeting ja ausmacht, dadurch nicht vollständig ersetzen lässt, werden wir über das parallele Streamen der Vorträge beim nächsten Onsite-PUM nachdenken.