
Business Intelligence beschäftigt sich hauptsächlich mit historischen Daten. Basierend auf einem bestimmten Datensatz versuchen wir, einen Blick in die Zukunft zu werfen und mögliche Trends vorherzusagen. Dafür sind Data Science-Methoden wie Predictive Analytics aber besser geeignet, weil sie Muster erkennen können, die sich wiederum auf andere Daten anwenden lassen. In diesem Artikel werde ich ein Modell für die Vorhersage von Verkäufen erstellen und es für eine Analyse verwenden. Im Mittelpunkt steht dabei der Prozess, d.h. die Entwicklung des Modells, seiner Implementierung und der abschließenden Analyse, und nicht die Entwicklung des besten Vorhersagemodells.
Ziel ist es, ein Modell zu erstellen, das den Umsatz eines Unternehmens vorhersagt. Konkret wollen wir den Preis vorhersagen, der durch den Verkauf von Haus und Grundstück in der Gemeinde King County erzielt werden kann. King County? Auf der Data-Science Plattform Kaggle gibt es einen Datensatz, der über einen Zeitraum von einem Jahr Daten gesammelt hat. Der Datensatz ist für erste Projekte im Predictive Analytics-Bereich gut geeignet, weil er eine überschaubare Anzahl von Parametern aufweist und wir mit relativ wenig Aufwand ein gutes Modell für die Vorhersage erstellen können. Für den Download der Daten muss man sich lediglich auf der Plattform registrieren (aus lizenzrechtlichen Gründen können wir den Datensatz hier nicht direkt zum Download anbieten).
1. Schritt: Auswahl der Software

2. Schritt: Die Daten
Mit Hilfe des Weka Explorers erstellen wir unser Vorhersagemodell. Im Tab Preprocess können wir uns einen ersten Überblick über die Daten verschaffen – welche Spalten gibt es im Dataset und wie sehen die Daten in den einzelnen Spalten aus?

Dazu müssen wir zuerst unseren Datensatz öffnen. Wir klicken auf den Button Datei öffnen… und navigieren zu unserer Datei. Damit sie angezeigt wird, müssen wir den Dateifilter von Arff auf CSV umstellen.
Jetzt sehen wir eine Liste der einzelnen Attribute. Wir können uns durch diese Attribute klicken und erhalten in der rechten Hälfte des Fensters detaillierte Informationen über sie. Werfen wir einen Blick auf das Attribut Badezimmer: man sieht, dass der Wertebereich für dieses Attribut zwischen 0 und 8 liegt und dass das durchschnittliche Haus in unserem Datensatz zwei Bäder hat. Visuell wird die Verteilung auch als Balkendiagramm dargestellt. Daraus lässt sich ableiten, dass Häuser mit mehr als vier Badezimmern die seltene Ausnahme sind.

Um die Daten besser kennen zu lernen, ist es ratsam, explorativ vorzugehen. Wir betrachten also zunächst jedes Attribut einzeln, um uns einen Überblick über den Wertebereich zu verschaffen und festzustellen, ob fehlende Werte vorhanden sind. Glücklicherweise ist das nicht der Fall, sodass wir uns darüber keine Sorgen machen müssen.
3. Schritt: Das Vorhersagemodell
Wie bereits erwähnt, geht es in diesem Artikel nicht darum, das beste Vorhersagemodell zu erstellen. Normalerweise würde man viel Zeit investieren, um die passenden Attribute auszuwählen oder gar neue Attribute zu definieren. Uns geht es darum, den Prozess aufzuzeigen, der zu einem fertigen Modell führt.
Um herauszufinden, welchen Einfluss die einzelnen Attribute auf unser vorherzusagendes Attribut Preis haben, messen wir die Korrelation (Pearson) zwischen ihnen. Dazu wechseln wir auf den Tab Select attributes und wählen CorrelationAttributeEval als Attribute Evaluator. Wir werden aufgefordert, die Search-Method auf Ranker zu ändern – dies bestätigen wir dann einfach im Popup-Fenster.

Was passiert nun hier? Wir messen die Korrelation zwischen zwei Variablen: In unserem Fall die Beziehung zwischen einem Attribut und dem Preis (da wir diesen vorhersagen wollen). Die Ausgabe von Pearsons Korrelation liegt im Wertebereich von -1 bis 1, was bedeutet:
| Korrelation | Bedeutung | Beispiel | Erklärung |
|---|---|---|---|
| 0 | keine Korrelation | Hausnummer und Geschlecht | X und Y haben keine Verknüpfung |
| > 0 | positive Korrelation | Temperatur und verkauftes Speiseeis | Höheres X führt zu höherem Y |
| < 0 | negative Korrelation | Kinopreis und Anzahl Besucher | Höheres X führt zu niedrigerem Y |
Das Ergebnis der Korrelation wird für jedes Attribut nach einem Klick auf Start angezeigt, absteigend sortiert von positiver zu negativer Korrelation. Wir sehen, dass folgende Attribute eine hohe positive Korrelation zu dem Attribut Preis aufweisen:
- sqft_living
- grade
- sqft_above
- sqft_living15
- bathrooms
Die Daten werden in der Regel in Trainings- und Testdaten unterteilt. Der Trainingssatz enthält eine bekannte Ausgabe und das Modell lernt mit diesen Daten, um die Erkenntnisse später auf andere Daten anwenden zu können.
Da wir über ein Gesamtdatenset (Total Set) verfügen, müssen wir zunächst das Training Set und das Test Set erstellen. Üblicherweise wählt man ein Verhältnis von 80:20 oder 70:30 für das Training/Testen. Das folgende Python-Skript unterteilt unseren Datensatz in einen Trainingssatz (80%) und einen Testsatz (20%) und speichert die beiden als train.csv und test.csv.
Um unser Modell zu erstellen, verwenden wir nicht das aktuell geöffnete Total Set, sondern den Trainingsdatensatz, den wir gerade erstellt haben. Wir wechseln daher zurück zum Reiter Preprocess und öffnen die Datei train.csv. Mit Hilfe der Korrelationsanalyse haben wir bereits herausgefunden, welche Attribute in Beziehung zum Attribut Preis stehen und daher als Input in das Modell einfließen sollten. Aus diesem Grund entfernen wir alle anderen Attribute, indem wir sie markieren und dann auf Remove klicken. Das Ergebnis sieht wie folgt aus:
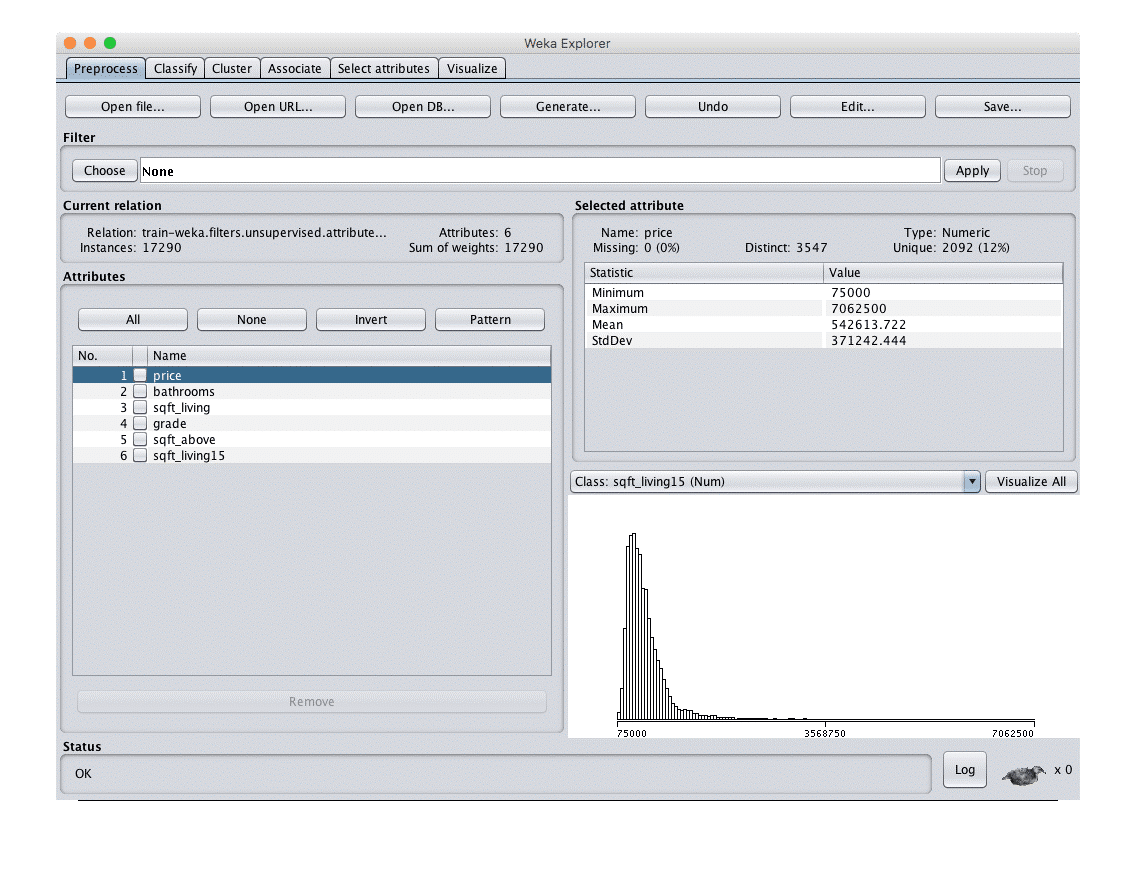
Jetzt sind wir an dem Punkt angelangt, an dem wir unser Modell erstellen können. Dazu wechseln wir auf den Reiter Classify. In dieser Registerkarte können wir aus einer Vielzahl verschiedener Algorithmen den Algorithmus auswählen, der am besten zu unserem Problem passt. Ich habe den Random Forest Algorithmus gewählt, um die Regressionsanalyse durchzuführen. Auf den Algorithmus näher einzugehen, würde den Rahmen dieses Artikels sprengen. Wer mehr über die Regressionsanalyse mit Random Forest in Weka wissen möchte, dem empfehle ich, diesen Artikel zu lesen.
Zuerst müssen wir das Feld auswählen, das vorhergesagt werden soll. Da wir den Preis des Hauses vorhersagen wollen, wählen wir den Preis aus der Dropdown-Liste. Wir müssen auch sicherstellen, dass die Option Use training set als Testoption ausgewählt ist. Nun klicken wir auf Start und unser Modell wird generiert – das kann einige Zeit in Anspruch nehmen. Wenn Weka die Regressionsanalyse mit Hilfe von Random Forest abgeschlossen hat, erscheint ein Eintrag in der Ergebnisliste und wir können das Modell exportieren, indem wir mit der rechten Maustaste darauf klicken und den Eintrag Save model wählen.

In diesem Screenshot sieht man in dem weißen Bereich u.a. auch 2 Prozentzahlen. Eine dieser Zahlen ist RMSE (Root Means Squared Error). Root Means Square Error wird häufig in der Klimatologie, bei Prognosen und bei der Regressionsanalyse verwendet, um experimentelle Ergebnisse zu verifizieren. Bei dieser Zahl handelt es sich um die Standardabweichung der Vorhersagefehler. Sie ist ein Maß dafür, wie weit die Datenpunkte von der Regressionslinie abweichen.
Das war es soweit mit Weka – wir haben ein Modell erstellt und exportiert. Weiter geht’s mit Pentaho.
4. Schritt: Das Modell auf unbekannte Daten anwenden
Das Weka Scoring Plugin ist ein Tool, um Klassifikations- und Clustering-Modelle, die mit Weka erstellt wurden, auf neue Daten anzuwenden. Scoring bedeutet in diesem Zusammenhang, eine Vorhersage zu machen und diese dem Datensatz hinzuzufügen.
Wir starten Pentaho Data Integration, das Datenintegrationsmodul von Pentaho, und erstellen eine simple ETL-Transformation. Am Anfang lesen wir die Datei test.csv ein, die wir uns zuvor aus dem Total Set erstellt haben. Anschließend verwenden wir das Weka Scoring Plugin, um die Preise mit Hilfe unseres Modells vorherzusagen.

5. Schritt: Das Modell laden
Wir können nun unser zuvor gespeichertes Modell in Pentaho Data Integration verwenden. Dazu öffnen wir den Schritt Weka Scoring und wählen es aus:

Erinnern wir uns, dass wir vorher fünf Attribute anhand der Pearson-Korrelation bestimmt haben, die wir als Input für unser Modell verwendet haben. Diese Attribute müssen nun wieder als Input zur Verfügung stehen. In der Registerkarte Fields mapping können wir überprüfen, ob die benötigten Attribute vorhanden sind und ob die Datentypen passen. Zusätzlich zeigt uns das Plugin im Reiter Modell unseren Baum (Random Forest) an und wie die Entscheidungen getroffen werden.
Zum Schluss starten wir unsere Transformation und stellen fest, dass der Weka Scoring Step eine neue Spalte in unserem Datensatz hinzugefügt hat – nämlich price_predicted. Mit diesem neuen Wert lassen sich also jetzt die Verkaufspreise im King County vorhersagen.
Fazit
Fassen wir noch einmal zusammen, was wir gemacht haben. Wir haben begonnen, uns einen ersten Überblick über unsere Daten zu verschaffen, indem wir die einzelnen Attribute genauer unter die Lupe nahmen. Dann wurden mit Pearsons Correlation diejenigen Attribute bestimmt, die für die Vorhersage des Preises geeignet sind. Diese wurden anschließend für unser Modell ausgewählt. Im Anschluss daran haben wir einen Teil der Daten (den Trainingsdatensatz) zur Erstellung unseres Modells verwendet, das wir anschließend exportiert haben. Durch den Einsatz von Pentaho Data Integration konnten wir dann mit diesem Modell den Preis vorhersagen – mit Daten, die der Algorithmus vorher nicht kannte.
Durch Predictive Modelle lassen sich also mit Daten aus der Vergangenheit Vorhersagen über Entwicklungen in der Zukunft treffen. Der Aufwand hierfür ist überschaubar und die Kosten auch, denn alle eingesetzten Instrumente sind als Open Source-Version frei verfügbar.
Diese Artikel könnten Sie auch interessieren: