
Die Auswertung riesiger Datenbestände durch den Fachanwender wird immer wichtiger. Der Großteil der Business Intelligence-Lösungen tut sich aber noch schwer damit. Aus diesem Grund haben wir die BI-Plattform Jedox mit Hive on Spark kombiniert. Damit lassen sich riesige Datenmengen komfortabel in einer Software bearbeiten und analysieren – auch durch IT-fremde Fachanwender wie Controller.
Apache Spark ist ein Open Source-Projekt aus dem Bereich Cluster Computing zur Verarbeitung von großen Datenmengen. Spark ist für einige Anwendungsfälle bis zu hundertmal schneller als MapReduce, weil es versucht, im Gegensatz zu MapReduce über Hadoop viele Operationen bei der Datenverarbeitung im Arbeitsspeicher durchzuführt (In-Memory) und so die Zugriffe auf das HDFS gering hält. Davon profitieren insbesondere Anwendungen mit vielen Reduce-Schritten wie sie z.B. bei der Übersetzung von komplexen Queries oder im Business Intelligence-Umfeld an der Tagesordnung sind.
Für Datenauswertungen bedeutet das einen großen Schnelligkeitsgewinn. Spark und Jedox wurden bislang jedoch noch nicht zusammen eingesetzt. Um zu testen, ob sich tatsächlich Performancegewinne aus der Kombination beider Lösungen ergeben, haben wir entsprechende Messungen vorgenommen. Dabei war es nicht nötig, Anpassungen an den Queries oder an Jedox vorzunehmen. Eine genaue Beschreibung der Messungen und des Messszenarios finden sich in diesem Dokument.
Testmessungen mit Hive on Spark und Jedox
Um messen zu können, wie die Leistung von Hive on Spark in Verbindung mit Jedox ist, haben wir mit drei verschiedenen Queries Messungen durchgeführt. Als Testdaten dienten uns Flugdaten aus den USA von Januar 2014 bis August 2015, ein http://www.transtats.bts.gov/e frei verfügbarer Datensatz mit ca. 8,2 Millionen Zeilen.Die erste Messung, eine einfache Scan Query, diente dazu, den Datensatz nach den Daten vom März 2014 zu filtern. Die zweite Messung bestand aus einer Aggregation Query und hatte zum Ziel, die Anzahl aller Zeilen der Datenbank auszugeben. Als letztes haben wir eine für das BI-Umfeld realistische Query erzeugt, welche die Anzahl aller verspäteten Flüge ausgibt und nach Fluggesellschaft gruppiert. Dafür sind mehrere Join- und Aggregationen-Operationen notwendig. Die folgenden Queries wurden jeweils über die Datenvorschaufunktion ausgeführt. Durch das Setzen eines entsprechend hohen Limits wurde auch beachtet, dass das gesamte Ergebnis der Query in der Datenvorschau angezeigt wird.

Die Queries mit den längsten Laufzeiten im BI-Umfeld kommen allerdings beim Beladen der Datencubes und Dimensionstabellen vor. Wir haben deshalb in einem nächsten Schritt die Eignung von Spark für diesen Einsatzzweck untersucht. Dazu haben wir diverse Load-Typen wie Dimension-Load, Cube-Load und eine Kombination der beiden Varianten untersucht. Zusätzlich haben wir die Verarbeitungsgeschwindigkeiten beim Schreiben in eine Datei betrachtet. Dadurch werden eventuelle Bottlenecks z.B. durch den Ladeprozess in die In-memory DB ausgeschlossen. Wer den Aufbau der Messungen und Cubes genauer nachvollziehen möchte, findet hier eine detaillierte Beschreibung.
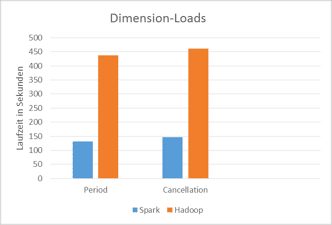
Beim Laden der Dimensionen „Period“ und „Cancellation“ konnten mit Spark Leistungssteigerungen von 334 % und 316 % erreicht werden.
Auch bei der Messung des Laufzeitverhaltens des Cube-Load gab es Effizienzgewinne: wie der Abbildung zu entnehmen ist, konnte das Laden des Würfels mit Spark um knapp 260 % beschleunigt werden.


Fazit: Kombination von Big Data-Technologien mit BI-Plattformen birgt großes Potenzial
Die Nutzung von Hive on Spark in Verbindung mit Jedox eröffnet ganz neue Möglichkeiten für die Aufbereitung und Auswertung von Big Data-Datenbeständen. Obwohl die vorgestellte Lösung mit einigen Einschränkungen verbunden ist, haben unsere Tests gezeigt, dass mit geringem Aufwand die Integration von Hive on Spark in Jedox möglich ist. Dadurch lassen sich Performancegewinne von bis zu 400% für Big Data Queries erreichen. Das betrifft insbesondere komplexe Queries mit vielen Joins und Aggregationen wie sie oft im Umfeld von Business Intelligence und Business Analytics vorkommen.Insbesondere die Ladeprozesse der Dimensionstabellen und Cubes durch Spark können durch die Kombination um bis zu 344 % erheblich beschleunigt werden. Da diese Art von Ladeprozessen in jedem Jedox Roll-out vorkommt, sollte unserer Meinung nach ein Hive on Spark-Einsatz grundsätzlich in Betracht gezogen werden, auch wenn sich die Spark-Unterstützung zum aktuellen Zeitpunkt noch in einem experimentellen Status befindet. Bei einer Weiterentwicklung von Hive on Spark ist mit noch größeren Leistungssteigerungen zu rechnen.
Trotz der deutlichen Vorteile von Hive on Spark gibt es leider auch einen kleinen Wermutstropfen: Momentan ist leider die Verbindung zu Spark noch experimentell und kann noch nicht direkt über die Oberfläche konfiguriert werden.